Airflow PostgreSQL to BigQuery Dynamically Generate DAGs and Tasks
Airflow is now a handy tool for almost all data engineers. If you have a common strategy for the data sync for many data sources, then we can just pass the sources via a loop and it’ll reuse the whole pipeline for everything. Most of you might already know about how to generate the Tasks dynamically. But in this post, Im going to share, how do we dynamically generate the DAGs as well as Tasks in Airflow alo it’ll generate the dag for different sync interval.
JSON config file: #
Im not sure how many of you a YAML fans, but I wanted to try with JSON. For YAML also, its a similar logic, but just use the YMAL library to extract the data from the config.
Scenario #
I have 10+ PostgreSQL database servers and I need to sync some of its tables to GCP BigQuery. Every time it has to be an incremental load. On the BigQuery side, the tables are super large (7TB+), so merging the delta data won’t be the right choice. So I did append-only load to the target table. A view is on top of it to de-dup the data. Duplicates on the Main table will be deleted weekly. I Will talk about it in my next blog.
Pre-Configurations: #
Im following some strict naming conversion for everything.
I have 10+ sources right? So I have the connections on the Airflow with the following conversion.
<env>_<db_engine>_<ip_address>_<dbname>
eg:
prod_postgres_10.10.10.11_platformdb
We can have the naming conversion till IP address, but I had some issues while generating the dynamic tasks, so multiple tasks will get the same task name.
Extracting is not a straightforward one, I had some custom logic to extract the data. So every time, I need to run a specific query for each table and that result will go to BQ. So I created SQL files for every table with the proper SQL select query. And that naming conversion as follows,
<source_export>_<schema_name>_<table_name>_<airflow_conn_name_for_that_database_server>.sql
eg:
source_export_transactions_paiddata_prod_postgres_10.10.10.11_platformdb.sql
These naming conversions will help to dynamically select the SQL files. You’ll get to know once you see the config file.
Finally, the JSON schema file - BQ load from the API must need a JSON schema file to load the data into the table, So I have generated such schema files with the following naming conversion.
<schema_name>_<table_name>.json
Meta Table: #
In my case, I want to maintain everything on the GCP side, the source databases were on the on-prem side. And I don’t want to spin up a VM or CloudSQL just to store the metadata. So I used the BQ table to store the metadata. In the Metadata table, I keep track of the max_timestamp value of the last load. So next time, the highest value will be pick from that.
Note: Make sure the value for the datasource_dbconn must be your Airflow connection id. Because the naming conversion will play a major role here.
Here is the table DDL.
-- databaseid and datasource_dbconn is used in our use case
-- you can skip those columns
CREATE TABLE
bqdataset.tablemeta (id INT64 NOT NULL,
tablename STRING NOT NULL,
datbabaseid INT64,
datasource_dbconn STRING NOT NULL,
maxvalue STRING NOT NULL)
Custom PostgreSQL Operator: #
The native PostgreSQL to GCS operator is not converting the timestamp and some other columns properly. So I wanted to make some changes to this operator and ended up creating a custom operator called custom_PostgresToGCSOperator. You can read more about this and get that operator here
SQL file to extract max timestamp value from source: #
We generally don’t use select max(ts) from table because we want to sync some specific records only. And for each table the logic is different. So in this DAG, I used SQL files for each table to find the max timestamp value. Its again optional, but replace the code accordingly.
Naming Conversion:
maxts_<schema>_<table>_<airflow-conn-name>.sql
eg:
maxts_trans_movie_subscriptions_prod_postgres_10.10.10.82_source.sql
-- Sample SQL to find the max ts
SELECT cast(Max({}) as varchar(40))
FROM trans.movie_subscriptions
WHERE database_id=1 and state='success'
and {}>='{}';
These to {} will be the max ts value column name and this value from the meta table.
SQL file for export: #
Data export also not the simple select *. I had to export via some specific SQL queries. So all the export processes will read the SQL file and export the data in CSV into GCS.
Naming Conversion:
source_export_<schema>_<table>_<airflow_conn_id>.sql
eg:
source_export_transactions_pat_prod_postgres_10.10.10.82_source.sql
-- sample export SQL
select
tbl1.id,
tbl1.transid,
tbl1.databaseid,
tbl1.cluster,
tbl1.time_modified,
case
when tbl1.jcol::json ->>'renewal' = '' then 0
else (tbl1.jcol::json ->>'renewal')::int
end renewal,
tbl1.update_timestamp
from
transactions.pat tbl1
inner join transactions.job tbl2 on
tbl1.id = tbl2.params_id
where
tbl1.update_timestamp >= '{}' and tbl1.update_timestamp <='{}';
Config File Template: #
I have the data sync for different tables and different time interval. So this template should have the following information.
- Cron interval (based on that, we’ll make the cron syntax)
- Schema name and Table Name
- Airflow database connection name to talk to the source DB
- Timestamp column name to pick the max timestamp value.
My config file template: #
{
"2mins": {
"platform.vouchers.movie_vouchers": ["updated_at", "prod_postgres_10.10.10.71_platform"],
"databaseid_1.plan.subscription": ["update_timestamp", "prod_postgres_10.10.10.82_source"],
"databaseid_2.plan.subscription": ["update_timestamp", "prod_postgres_10.10.10.86_subscriptions"]
},
"30mins": {
"test.top.file": ["update_timestamp", "prod_postgres_10.10.10.73_micorservices"],
"test.top.ticket": ["update_timestamp", "prod_postgres_10.10.10.73_micorservices"],
"databaseid_1.transactions.payment": ["update_timestamp", "prod_postgres_10.10.10.82_source"],
"databaseid_2.transactions.payment": ["update_timestamp", "prod_postgres_10.10.10.191_source"],
"databaseid_1.transactions.gateway": ["update_timestamp", "prod_postgres_10.10.10.82_source"],
"databaseid_2.transactions.gateway": ["update_timestamp", "prod_postgres_10.10.10.191_source"],
"databaseid_1.transactions.master": ["update_timestamp", "prod_postgres_10.10.10.82_source"],
"databaseid_2.transactions.master": ["update_timestamp", "prod_postgres_10.10.10.191_source"]
}
}
Here, I have added some prefixes (platform.vouchers.movie_vouchers) before the table and schema name.
- platform - Prefix
- vouchers - Schema
- movie_vouchers - Table name.
Im going to generate the tasks based on this JSON KEY. So if we have the same schema and table name for multiple databases, the last task will replace the previous one. So the task must be unique, that’s why I added this prefix for some reference.
Pipeline Flow: #
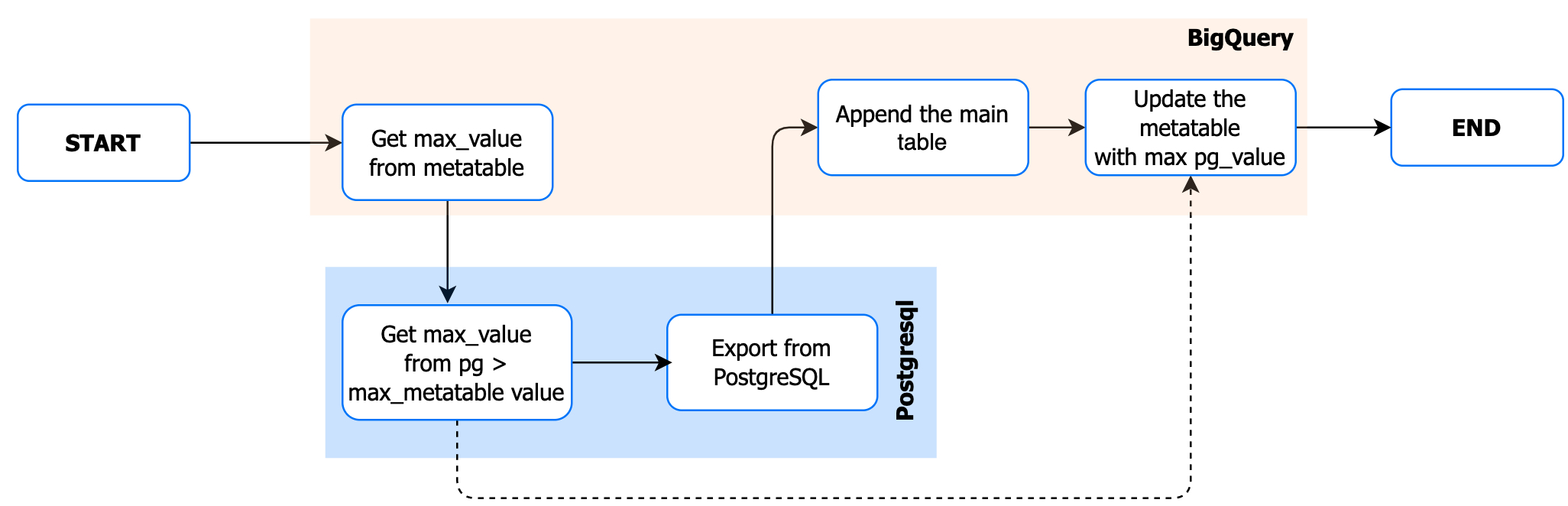
DAG Code: #
Things to replace: #
from customoperator.custom_PostgresToGCSOperator import custom_PostgresToGCSOperator- Its the location and operator name of my custom PostgreSQL operator.'email': ['[email protected]']- Mail ID of your team/home/airflow/gcs/dags/mergeload/config.json- Full path for the Config file.BigQueryHook(bigquery_conn_id='bigquery_default',location='europe-west3')- BQ connection ID in airflow and your dataset location in BQ.bqadmin.tablesync_meta- BQ metadata table./home/airflow/gcs/dags/mergeload/maxts_sql/- Path where the SQL query for getting the max timestamp for each table will be located.with open('/home/airflow/gcs/dags/mergeload/export_sql/source_export_'- Full path where export select SQL queries are located.google_cloud_storage_conn_id='google_cloud_storage_default'- Airlfow connection for GCSbucket='prod-data-sync-bucket'- GCS bucket to export the datafilename='mergeload/data/'.....- Prefix path in GCS to export the data.destination_project_dataset_table- I follow the BQ table names as<soruce_schemaname>.tbl_<source_tablename>, but schema name and table names must be same as source. Feel free to modify as per your needs.schema_object- JSON schema file for the table.
You can find the complete code base here, if you have any clear details, find it in the example codebase.