Analyze RedShift user activity logs With Athena
A few of my recent blogs are concentrating on Analyzing RedShift queries. It seems its not a production critical issue or business challenge, but keeping your historical queries are very important for auditing. RedShift providing us 3 ways to see the query logging. But all are having some restrictions, so its very difficult to manage the right framework for analyzing the RedShift queries. We can keep the historical queries in S3, its a default feature. We can get all of our queries in a file named as User activity log(useractivitylogs). But its a plain text file, in other words, it’s an unstructured data. Now you understand where the problem is. Lets see the challenges with all these 3 ways.
- useractivitylog in s3 - Completly unstructured, we can’t directly use this.
- STL_QUERY - Great table, but if your query is huge in size, then it’ll truncate your query, so you’ll not get the complete query.
- STL_QUERYTEXT - This table contains the full query, but unfortunately one single query split into multiple rows, so we need to concat all these rows into a single row. Again in RedShift concat is not available, instead, we can use LIST_AGG, but it’ll support up to 65k charactors in a single group.
From the above three options, we can’t solve this issue with the help of RedShift, we need a different engine to solve this. So I picked AWS Athena which is cheaper. Now if you think which method will give you a complete query analyzing feature?
- STL_QUERYTEXT - Need to perform CONCAT but the data is structured.
- useractivitylog file - Unstructured, need some effort and customization to process it.
Some references: #
useractivitylog files can we easily analyzed with pgbadger an opensource tool to analyze the PostgreSQL logs. But it’ll not give you all the metrics like query execution, etc. But applying more filters is not possible. To read about this approach click this lik
STL_QUERYTEXT CONCAT process in RedShift with LIST_AGG also CONCAT process in Athena with ARRAY_AGG. But both methods are not full fledged solutions.
That’s why I want to bring another solution where I can see the complete queries and play around with many filters like username, update queries, alter queries, etc.
Solution Overview: #
- This file is also having many queries that will go more than a line, so you may see multiple new lines for a single query. We need to remove all of these new line charactors from all the log files.
- Athena can’t directly scan these files from its default S3 location, because RedShift will export 3 different files at every 1hr, so Athena will fail to query only on the useractivitylog files.
- Automate the whole steps for upcoming files as well.
I read a blog from PMG where they did some customization on these log files and built their dashboard, but it helped me to understand the parsing the files and so many python codes, and more filter, but I don’t want to do all those things. I just took a piece of code to remove the newline characters from the log file.
Approach: #
- Whenever the RedShift puts the log files to S3, use
Lambda + S3trigger to get the file and do the cleansing. - Upload the cleansed file to a new location.
- Create the Athena table on the new location.
- Create a view on top of the Athena table to split the single raw line to structured rows.
Create the lambda function: #
Create a new lambda function with S3 Read permission to download the files and write permission to upload the cleansed file. No need to run this under a VPC. You have to change the following things as per your setup.
- redshift-bucket - S3 bucket name where the RedShift is uploading the logs.
- log_folder - S3 prefix where the log files are stored. (you need this while creating the S3 trigger)
- custom-log-path - S3 prefix where the new cleaned will be uploaded.
file_name = key.split('/')[8]- In my s3 bucket the files are located with the following format.
s3://bucketname/log_prefix/AWSLogs/Account-ID/Cluster-name/region/YYYY/MM/DD/
- From the the Prefix to DD folder I need to jump 8 Folders to reach my files, so I have given 8, if you use more than one folder as a RedShift Prefix, please count the folder and replace 8 with your value.
import json
import urllib
import boto3
import re
import gzip
#S3 client
s3 = boto3.client('s3')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
#get the file name from the key
file_pattern='_useractivitylog_'
file_name = key.split('/')[8]
key_path=key.replace(file_name,'')
if file_pattern in key:
with open('/tmp/'+file_name, 'wb') as f:
#download the file
s3.download_fileobj('redshift-bucket', key, f)
#extract the content from gzip and write to a new file
with gzip.open('/tmp/'+file_name, 'rb') as f,open('/tmp/custom'+file_name.replace('.gz',''), 'w') as fout:
file_content = str(f.read().decode('utf-8'))
fout.write(file_content)
#read lines from the new file and repalce all new lines
#Credits for this piece PMG.COM
with open('/tmp/custom'+file_name.replace('.gz',''), 'r', encoding='utf-8') as log_file:
log_data = log_file.read().replace('\n', ' ')
log_data = re.sub(r'(\'\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}Z UTC)', '\n \\1', log_data)
newlog = re.sub(r'^\s*$', '', log_data)
#write the formatter lines to a file
with open('/tmp/cleansed_'+file_name.replace('.gz','')+'.txt', 'w') as fout:
fout.writelines(newlog)
#upload the new file to S3
s3.upload_file('/tmp/cleansed_'+file_name.replace('.gz','')+'.txt', 'redshift-bucket', 'custom-log-path/'+key_path+file_name.replace('.gz','')+'.txt')
else:
print("Skipping")Create the Athena Table: #
CREATE EXTERNAL TABLE `activitylog`(
`logtext` varchar(20000))
ROW FORMAT DELIMITED
LINES TERMINATED BY '\n'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://redshift-bucket/custom-log-path/'Create View to split the row into columns: #
CREATE OR replace VIEW v_activitylog
AS
SELECT Cast(Replace(Replace(Substring(logtext, 3, (
Strpos(logtext, 'UTC') - 3 )
), 'T',
' '), 'Z', '') AS TIMESTAMP)
timestamp,
Replace(Substring(Substring(logtext, (
Strpos(logtext, 'db=')
+ 3 ))
, 1,
Strpos(Substring(logtext, (
Strpos(logtext, 'db=')
+ 3 )),
' ')), ' ', '')
db
,
Replace(Substring(Substring(logtext,
( Strpos(logtext, 'user=') + 5
)), 1,
Strpos(Substring(logtext, (
Strpos(logtext, 'user=') + 5 )),
' ')), ' ', '')
user,
Cast(Replace(Substring(Substring(logtext, (
Strpos(logtext, 'pid=')
+ 4 )
), 1,
Strpos(Substring(logtext, (
Strpos(logtext, 'pid=') + 4
)), ' '))
,
' ', ''
) AS INTEGER)
pid,
Cast(Replace(Substring(Substring(logtext, (
Strpos(logtext, 'userid=') +
7 )), 1,
Strpos(Substring(logtext, (
Strpos(logtext, 'userid=')
+ 7 )), ' ')), ' ', '') AS
INTEGER
)
userid,
Cast(Replace(Substring(Substring(logtext, (
Strpos(logtext, 'xid=')
+ 4 )
), 1,
Strpos(Substring(logtext, (
Strpos(logtext, 'xid=') + 4
)), ' '))
,
' ', ''
) AS INTEGER)
xid,
Substring(logtext, ( Strpos(logtext, 'LOG:') + 5 ))
query
FROM activitylog
WHERE logtext != ''; Query the Data: #
Everything is ready for analysis. Let’s run some sample queries.
select * from v_activitylog limit 10;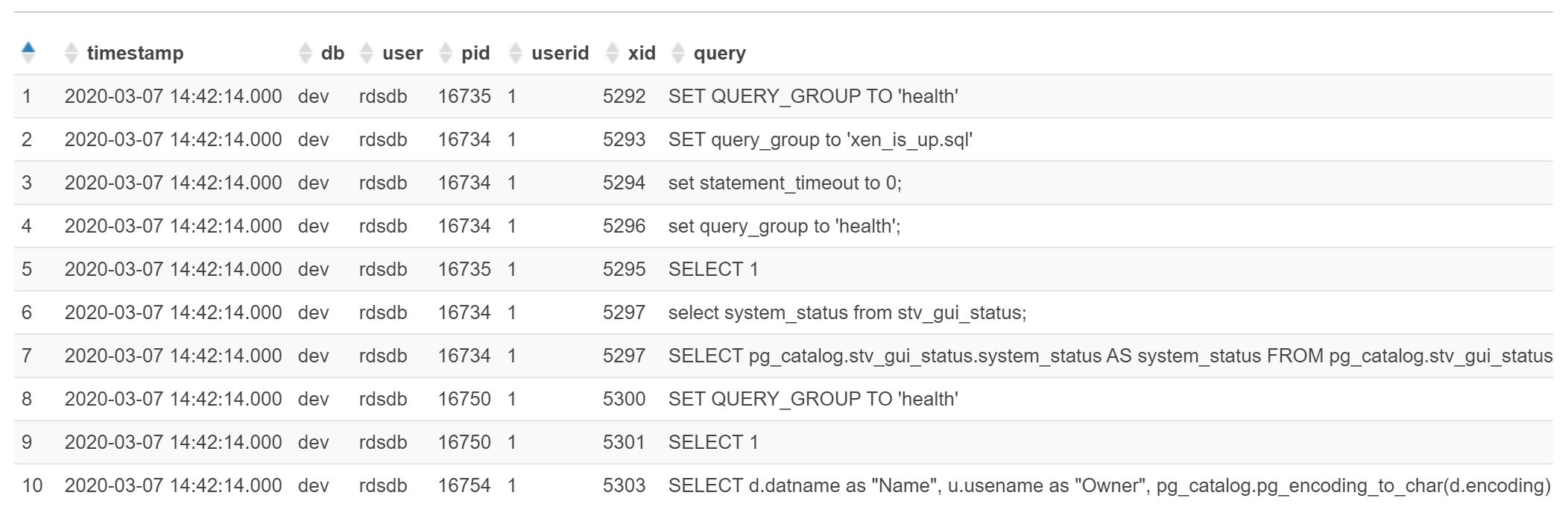
select * from v_activitylog where user!='rdsdb';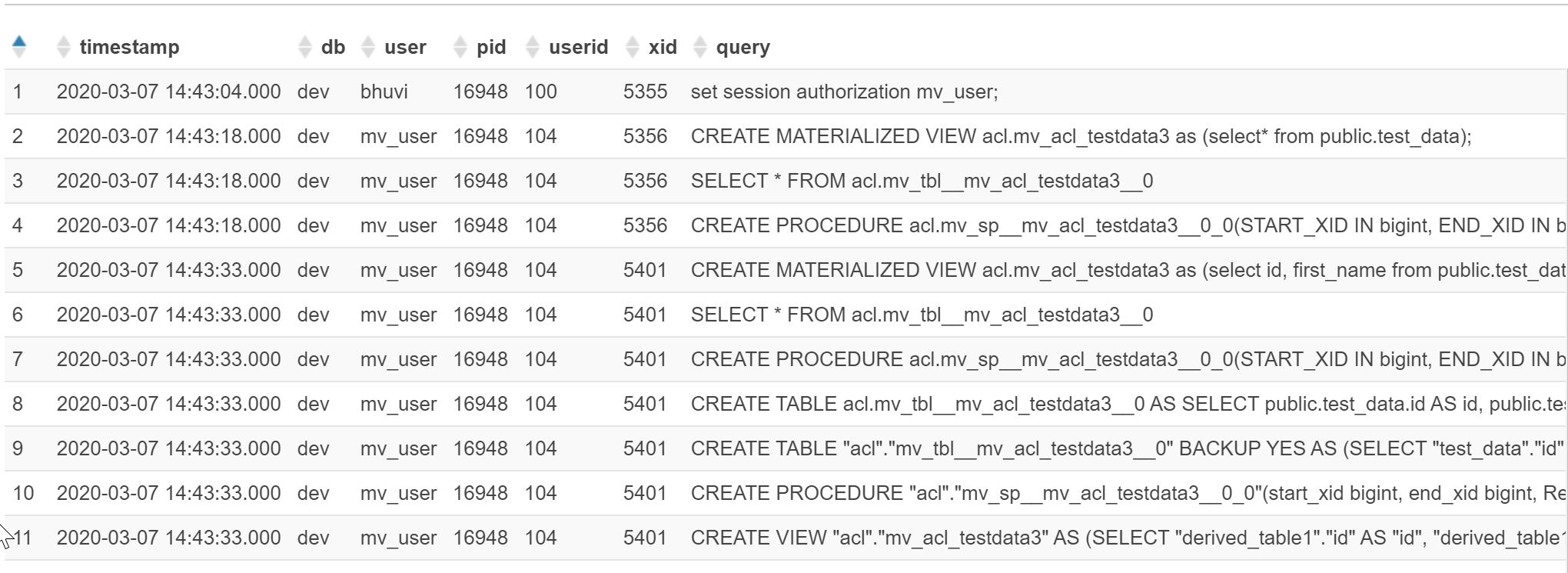
select user,count(*)as count from v_activitylog group by user;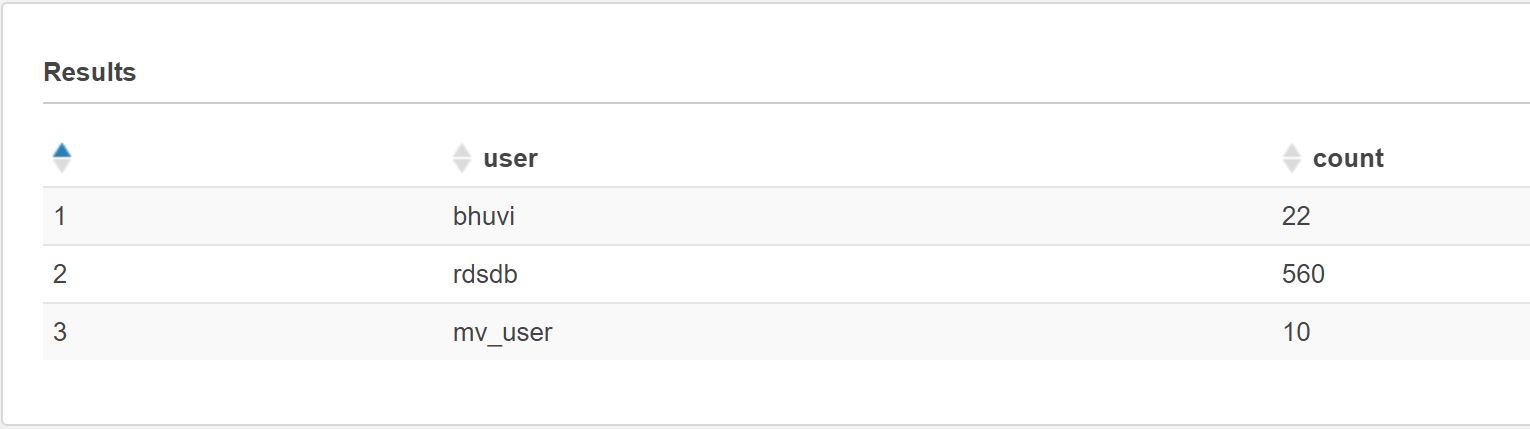
Next Announcement: #
Here we are extracting the user, query, pid and everything with SQL operations which is a bit costly operation, but to leverge the Bigdata’s features we can use Gork pattern in Glue to crawl the data and create the table. Unfortunatly Im facing an issue with the Grok patten, may be I’ll publish that as a new blog, that will save your execution time.
How about Spectrum? #
Yes, you can use the same DDL query to create your external table and (I hope everything will work fine there as well).
Update: 2020-05-28 #
I have added a new blog where we can use Glue Grok patten as a custom classifier to query the useractivity log data. Read the blog here.
https://thedataguy.in/redshift-userctivitylog-specturm-glue-grok-classifier