AWS DocumentDB - A NoSQL Equivalent For Aurora
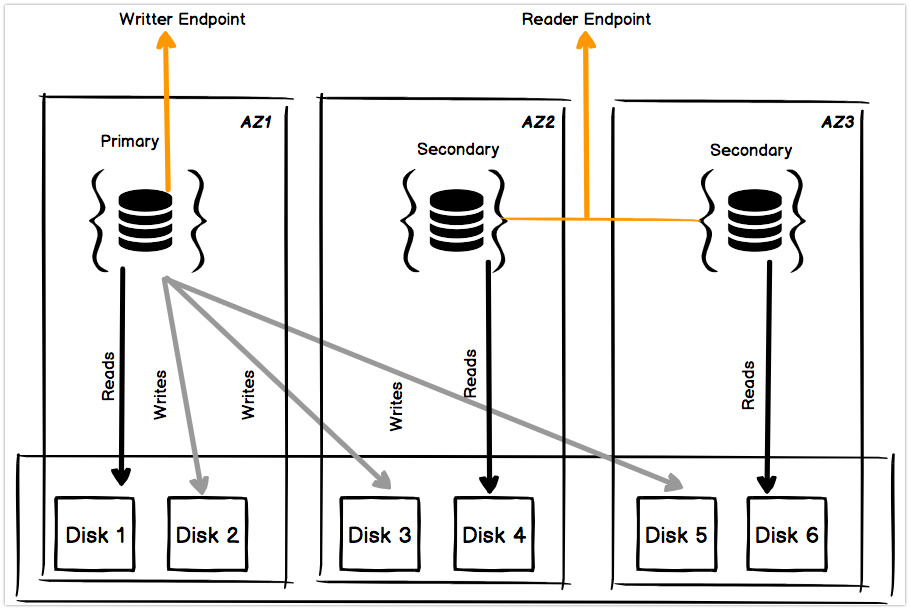
As we all know that AWS announced the managed MongoDB services called as AWS DocumentDB. MongoDB is one of my favourite NoSQL Databases even for developers. Since Im working with MongoDB in AWS, its the very first step setting up the replica set and shards. It’ll take a couple of mins to configure. But setting up the monitoring and other stuffs like troubleshooting replication issue, resync the failed replica and fixing issues in sharding is a big headache for DBAs. I guess even AWS felt the pain :)
Now we have the managed mongo clusters in AWS. The reason why Im writing this blog is, Im a very big fan of AWS Aurora. The designing concept is awesome. After aurora’s arrival, most of the MySQL workloads became very smooth and later PostgreSQL.
What AWS Document DB does? #
- MongoDB Compatible with 3.6.
- Fully managed.
- Works only inside the VPC.
- For public access we can use SSL tunneling from an EC2 instance or port farwarding.
- Upto 15 replicas.
- In-build load balancer for read workloads(reader endpoint).
- Priority based failover (assign which node to be failed over first).
- No need to for pre-provisioning the storage upfront.
- Scaleable storage upto 64TB. (automatically adds 10GB whenever it reaches the threshold)
- Automated snapshots upto 35days.
- Read Isolation - Kind of read committed mechanism for reader nodes.
- All mongoDB read preferences are supported. ( primary, primaryPreferred, secondary, secondaryPreferred, nearest).
Replication: #
While reading the above points, you may realize that, all of the features are very similar to Aurora. Yes, exactly it matches Aurora’s architecture. AWS DocumentDB is not using native mongodb replication mechanism. To understand its replication, let rewind how Aurora is handling the replication.
Aurora is using a clustered volumes which has 2 volumes in each availability zone and span across 3 zones. So totally 6 volumes are in that cluster. While writing something on the Clustered volume, it’ll write to all 6 volumes in parallel. Also its PIOPS volumes. From my previous experience aurora handled 40000 Write IOPS.
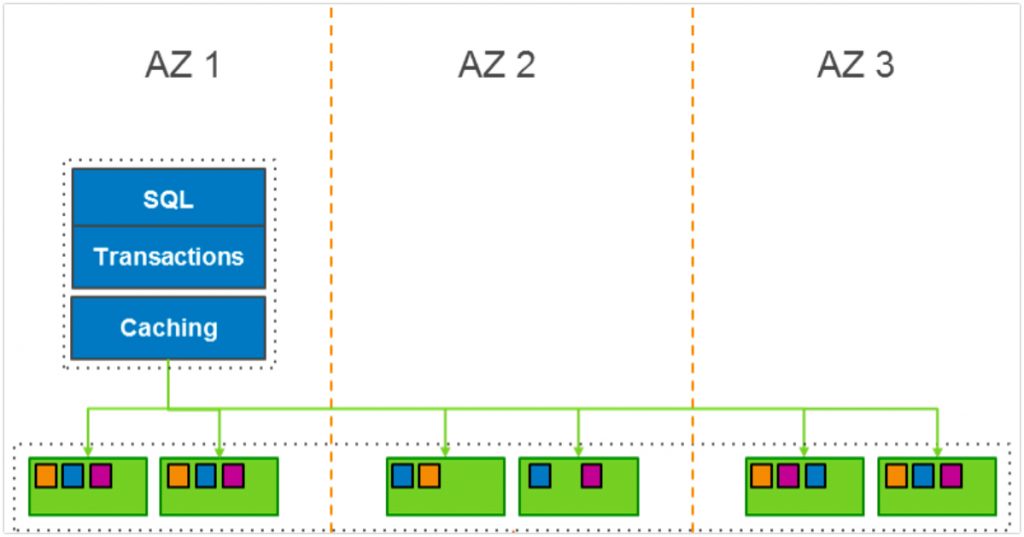
Now in DocumentDB its almost similar to Aurora’s write operation. Here it’ll use the replica set for maintaining the quorum and all but for data replication, instead of replicating the data its just replicate the state of the write to each replica. So there is no much write ops and it’ll improve the replication performance. AWS claims that usually it the lag is less than 100ms latency to replicate the state.
Cool features in AWS DoumentDB: #
Cache Warming: #
During the failover, AWS DocumentDB cache the frequetnly access data pages in memory. So after the failover still it holds the cache in Cache layer. So the new primary will not do Disk Reads even after failover.
Crash Recovery: #
If you mongo instance crashed and AWS tries to recover using asynchronous parallel threads. So the instance will be up as soon as possible.
Read Isolation: #
If you are familiar with Relational databases transaction isolation, then it’s almost same. While reading the data from reader instance, it’ll return the previously committed data.
Then how about sharding? #
You may come with this question, can we have shards in AWS DoucmentDB?
To answer this think about where we need the sharding. If we have massive write Ops from different geo locations, then sharding might help you to reduce your write latency and replication lag. But here its a clustered volume and also all the writes are performed in parallel on a PIOPS volumes. So according to me sharding is not necessary here. But to reduce latency in different geo locations then this statement is not correct.
What Im expecting from AWS for DocumentDB? #
- Global database - Aurora has globally distributed database service which is equivalent for Sharding.
- Version 4.0 or support for ACID - 4.0 has ACID compliance. But SSPL licensing an issue.
- Newer versions - Again refer the above point.
- Add external replica from EC2.
External Resources: #
- Limitations - https://docs.aws.amazon.com/documentdb/latest/developerguide/limits.html
- How its works - https://docs.aws.amazon.com/documentdb/latest/developerguide/how-it-works.html
- Create the cluster - https://aws.amazon.com/blogs/aws/new-amazon-documentdb-with-mongodb-compatibility-fast-scalable-and-highly-available/
- Aurora’s storage internal - https://aws.amazon.com/blogs/database/introducing-the-aurora-storage-engine/