AWS Glue Custom Output File Size And Fixed Number Of Files
AWS Glue is the serverless version of EMR clusters. Many organizations now adopted to use Glue for their day to day BigData workloads. I have written a blog in Searce’s Medium publication for Converting the CSV/JSON files to parquet using AWS Glue. Till now its many people are reading that and implementing on their infra. But many people are commenting about the Glue is producing a huge number for output files(converted Parquet files) in S3, even for converting 100MB of CSV file will produce 500+ Parquet files. we need to customize this output file size and number of files.
Why Glue is producing more small files? #
If you are processing small chunks of files in Glue, it will read then and convert them into DynamicFrames. Glue is running on top of the Spark. So the dynamic frames will be moved to Partitions in the EMR cluster. And the Glue partition the data evenly among all of the nodes for better performance. Once its processed, all the partitions will be pushing to your target. Each partition will and one file. That’s why we are getting more files.
Customize the output files: #
We can customize it in two ways.
- While reading the data from the source.
- While writing the data to the target.
If you have so many small numbers of files in your source, them Glue process them in many partitions. So we can force the Glue to read multiple file in one shot. Like we are grouping multiple file and the Glue virtually consider this as a single file.
Else, once you processed the data, you can repartition the data. So you can mention how many partitions you want. Let’s say if you repartition the data with 5, then it’ll write 5 files in your target.
Testing Infra setup: #
- I have 1GB of test data set.
- Format CSV
- Split into 20 files.
- Each file is 52MB.
- Created a Glue crawler on top of this data and its created the table in Glue catalog.
- Im using glue to convert this CSV to Parquet. Follow the instructions here: https://medium.com/searce/convert-csv-json-files-to-apache-parquet-using-aws-glue-a760d177b45f
Option 1: groupFiles #
From AWS Doc,
You can set properties of your tables to enable an AWS Glue ETL job to group files when they are read from an Amazon S3 data store. These properties enable each ETL task to read a group of input files into a single in-memory partition, this is especially useful when there is a large number of small files in your Amazon S3 data store.
groupFiles:
Set groupFiles to inPartition to enable the grouping of files within an Amazon S3 data partition. AWS Glue automatically enables grouping if there are more than 50,000 input files.
groupSize:
Set groupSize to the target size of groups in bytes. The groupSize property is optional, if not provided, AWS Glue calculates a size to use all the CPU cores in the cluster while still reducing the overall number of ETL tasks and in-memory partitions.
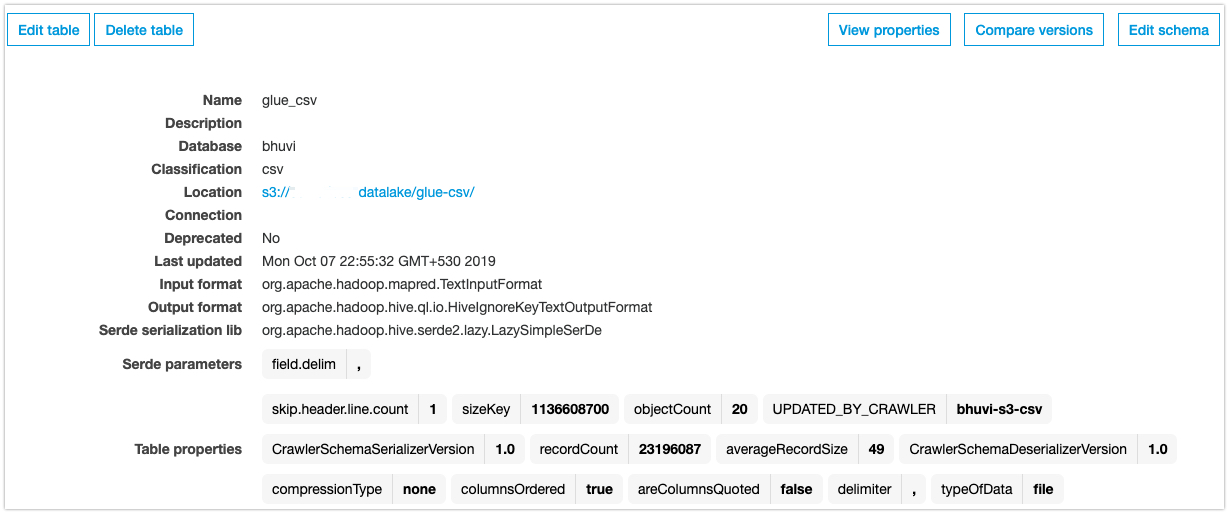
Go to Glue –> Tables –> select your table –> Edit Table.
Unde the table properties, add the following parameters.
groupFiles-inPartitiongroupSize-209715200
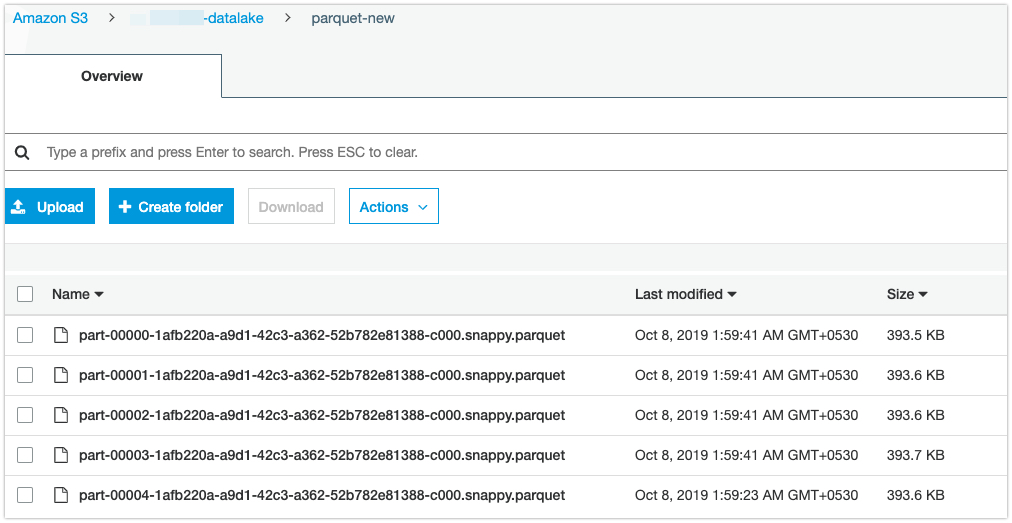
This will read 200MB data in one partition. Lets run the job and see the output.
- Total Number of files: 5
- Each file size: 393kb
Option 2: groupFiles while reading from S3 #
It’s the same as the previous one, but if you take a look at the datasource, its creating the dynamic frame from the catalog table.
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "bhuvi"
But if you are directly reading it from S3, you can change the source like below.
datasource0 = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://s3path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '104857600'}, format="csv")
Option 3: Repartition #
Once the ETL process is completed, before writing it to S3, we need to repartition it. The partition size is equal to the number of files you want in s3.
My current code as below.
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "bhuvi", table_name = "glue_csv", transformation_ctx = "datasource0")
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("ln", "string", "ln", "string"), ("gender", "string", "gender", "string"), ("ip", "string", "ip", "string"), ("fn", "string", "fn", "string"), ("id", "long", "id", "long"), ("email", "string", "email", "string")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": "s3://bhuvi-datalake/parquet-new"}, format = "parquet", transformation_ctx = "datasink4")
job.commit()Just add the repartition command above the write data frame line.
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "bhuvi", table_name = "glue_csv", transformation_ctx = "datasource0")
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("ln", "string", "ln", "string"), ("gender", "string", "gender", "string"), ("ip", "string", "ip", "string"), ("fn", "string", "fn", "string"), ("id", "long", "id", "long"), ("email", "string", "email", "string")], transformation_ctx = "applymapping1")
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
datasource_df = dropnullfields3.repartition(2)
datasink4 = glueContext.write_dynamic_frame.from_options(frame = datasource_df, connection_type = "s3", connection_options = {"path": "s3://bhuvi-datalake/parquet-new"}, format = "parquet", transformation_ctx = "datasink4")
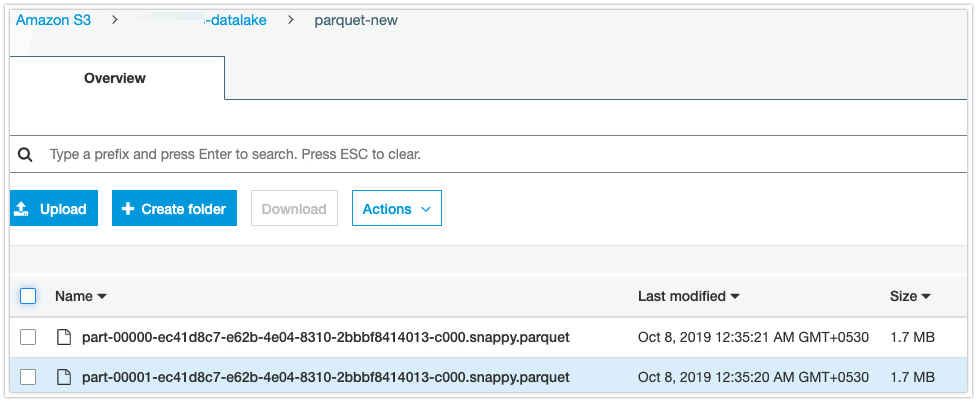
job.commit()repartition(2) - This will create 2 files in S3.
- Total files: 2
- Each file size: 1.7MB
Final words: #
From the above experiments, we can control the number of files for output and reducing the small files as output. But we can set the exact file size for output. Because Spark’s coalesce and repartition features are not yet implemented in Glue’s Python API, but its supports in Scala. I personally recommend using option 1.
Further Reading: #
I have found some useful information while doing this experiment. Im giving those links below.
- Reading Input Files in Larger Groups
- Connection Types and Options for ETL in AWS Glue
- How to use AWS Glue / Spark to convert CSVs partitioned and split in S3 to partitioned and split Parquet
- Combine multiple raw files into single parquet file
- AWS Glue FAQ, or How to Get Things Done
- DynamicFrame vs DataFrame
- DynamicFrame Class