Use AWS Glue DataBrew To Remove Any Sensitive And PII Information
AWS Glue DataBrew is a serverless service that helps data engineers to cleanse and format their RAW data without writing any single line of code. It’s announced just before reinvent 2020. It has 250+ build-in transformations which reduce the overall efforts for the transformation. In this post, I’ll show you how can we use this DataBrew to remove any PII and other sensitive information from the dataset.
Disclaimer: In this demo, I have used the dummy data which is generated from the https://www.mockaroo.com/.
Glue vs Glue DataBrew: #
- Ultimately both services used to perform ETL things. But Glue works with 100% code and the DataBrew works with 0% code.
- Glue can use any kind of transformation but the DataBrew works only with the build-in transformation(at least for now)
- DataBrew has a profiler where we can get some sense about the data, but glue doesn’t have something like this.
- DataBrew can get pull the data from S3 or tables from the Glue catalog or we can upload a file, but we can’t use any custom connectors like getting the data from salesforce or something is not possible.
Solution Overview: #
- The sensitive data is on the RedShift cluster
- The connection for the RedShift and the table is already created on the Glue data catalog.
- DataBrew will fetch the data from RedShift and clean the PII data then upload it to an S3 bucket.
Transformations: #
- Mock the mail ID with
dummy_mailbefore the@symbol and keep the domain name. - Mock the first 6 digits of the phone numbers with
123-123. - Keep only the last 4 digits of the CARD number and remove the rest of the numbers from the beginning.
- Rename the email and phone number column with
mock_emailandmock_phone.
DataBrew Tech terms: #
- DataSet - A table. It can be a single file or a bunch of files in S3 or a table from the Glue Data catalog.
- Project - A place to build your transformation.
- Recipe - A transformation logic.
- Job - A job that will apply the recipe on top of a dataset.
Sample Data: #
create table userdata (
id INT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50),
gender VARCHAR(50),
ip_address VARCHAR(20),
phone VARCHAR(50),
credit_card VARCHAR(50),
card_type VARCHAR(50),
transaction_id VARCHAR(40)
);
-- loading the data from S3.
COPY userdata from 's3://mybucket/raw/MOCK_DATA.csv' iam_role 'something something' CSV;
Data Preparation: #
Create dataset: #
Go the Glue DataBrew console and select the dataset. Then create a new Dataset. We already added this table into Glue, so select on database name where the table has located and select the userdata table. During the process, the DataBrew needs to get the data out from RedShift and do its process, it needs an S3 bucket to stage the files. So select the S3 path for this.
Create project: #
The project is the place where we build the transformation recipes. Create a new project and give a name. Under the recipe details select the Create new recipe.
- Select the dataset - My Dataset. We already created the dataset on the Brew, so select that dataset.
- Sampling - Number of rows will be taken for the sample in the Brew console for validation.
- Permissions - You need an IAM role that has managed
AWSGlueDataBrewServiceRolerole and a custom role toRead and Write objectsto the stage bucket and then the output bucket.
Once its created you can see sample data.
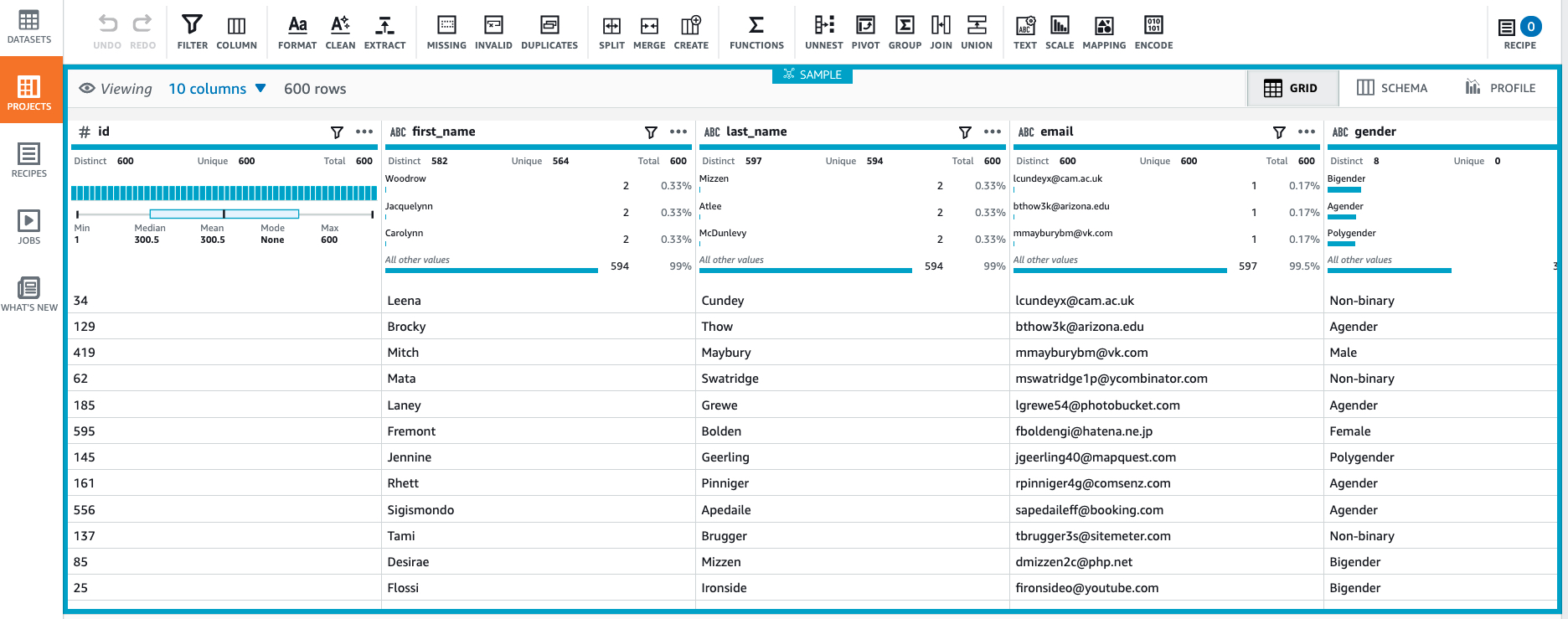
Mock the email address: #
Select the email column and from the menu select clean -> Replace -> Replace value or pattern.
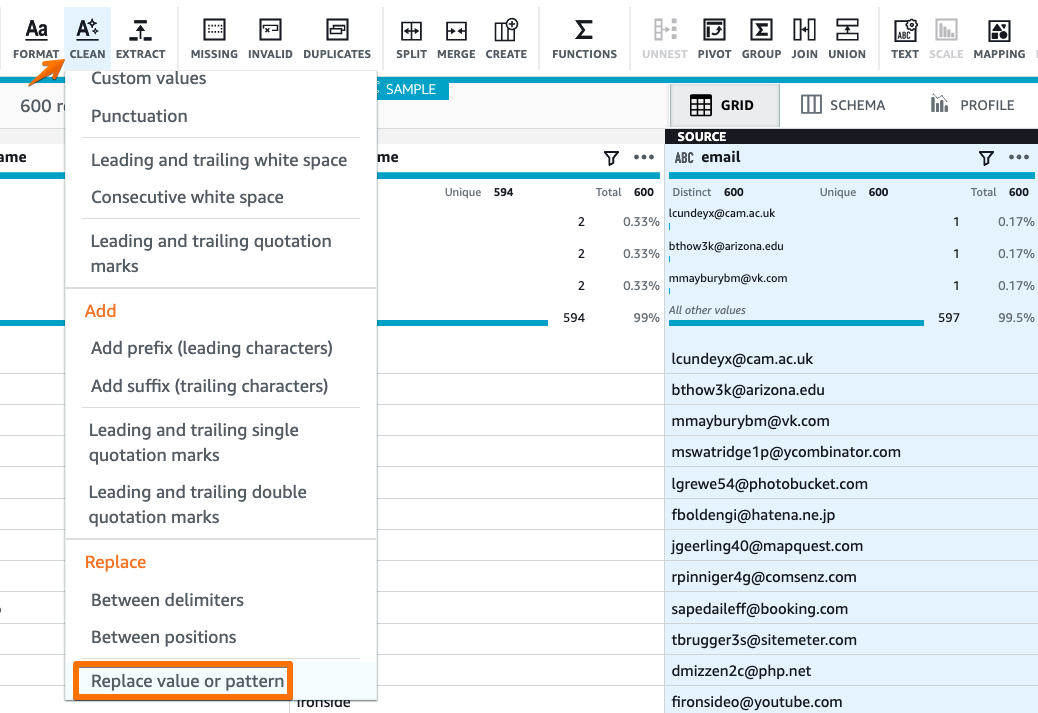
From the value to be replaced, select the Regex option and use the following regex as ^[a-zA-Z0-9+_.-]+@
Replace with value dummy_email@
Then click the apply button.
Mock the phone number column: #
This is also a regex-based replace.
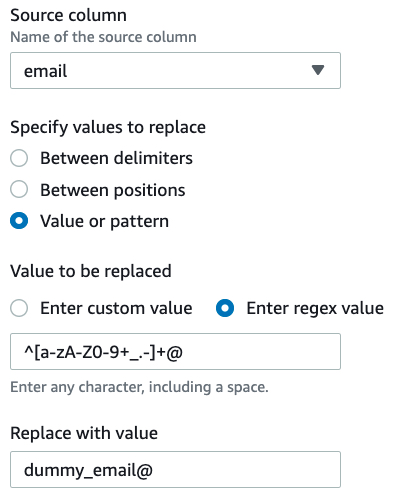
- Regex value
^[1-9]\d{2}-\d{3}- - Replace value
123-123
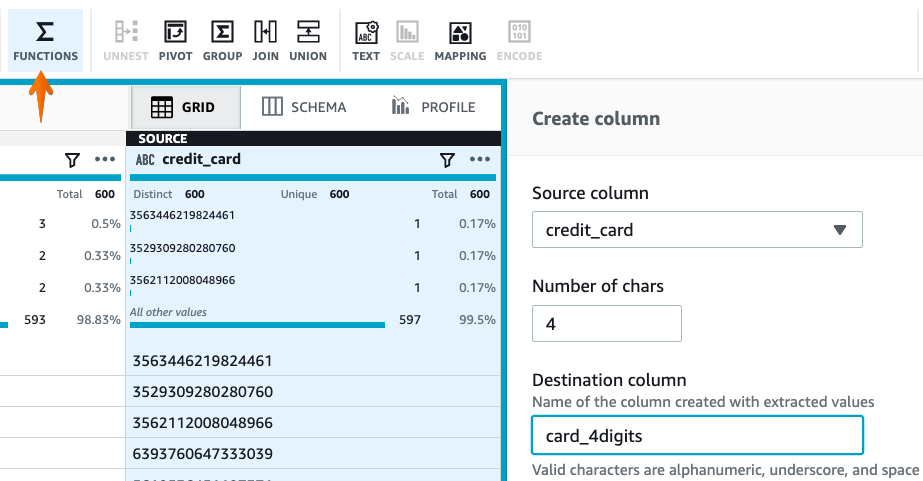
Keep last 4 digits in CARD number #
The sample data has a different format for the card numbers. It’s all integer but the total number of characters in the column is not the same. So we’ll create a new column with the last 4 digits from the CARD Number column and delete the original card number column.
- Select the column and in the menu bar select the
Functionoption -> Text -> Right. - Number of chars -
4 - Destination column name -
card_4digits
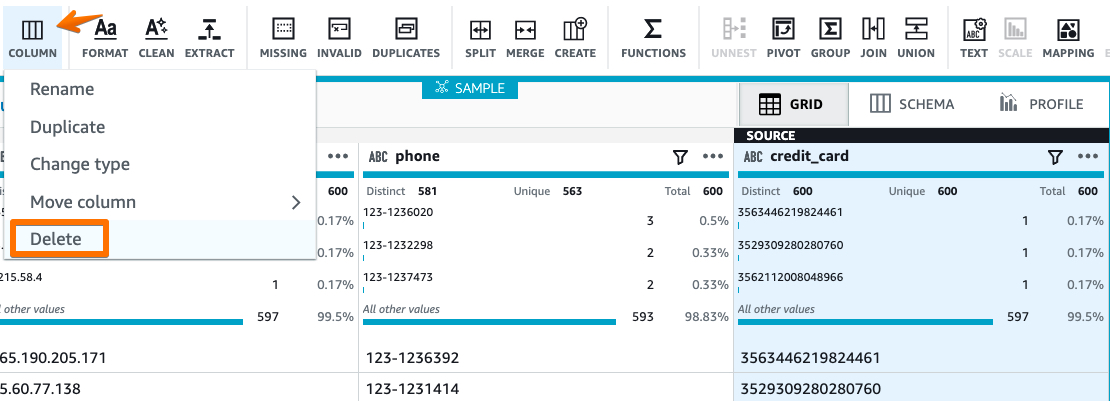
Delete the original CARD column: #
We don’t this original column, so select the column. From the menu bar select column -> Delete.
Rename the email and phone column: #
To indicate the columns are mocked, we will rename the columns as mock_email and mock_phone. Select column -> click the navigation dots -> Rename -> mock_email.

Repeat the same for the phone column.
Export the recipe: #
From the recipe section, you can see all the transformations. If you want to use this recipe on a regular basis or use it for other projects, we need to publish it. Also, you can export it as YAML and JSON.
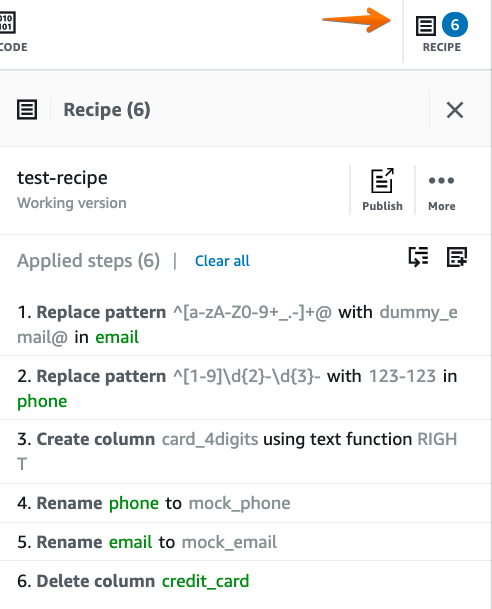
If you click on the lineage option, you can see the visual representation of this transformation.

Run the Job: #
This job is saved automatically, so you can directly click on the Create Job button on the right top corner or navigate to Glue DataBrew -> Projects -> select the project -> Run Job.
It’ll ask you to select the target S3 path where the cleansed data will be uploaded. You can add multiple paths(same data will be copied) with multiple formats like CSV, JSON, Parquet and etc.
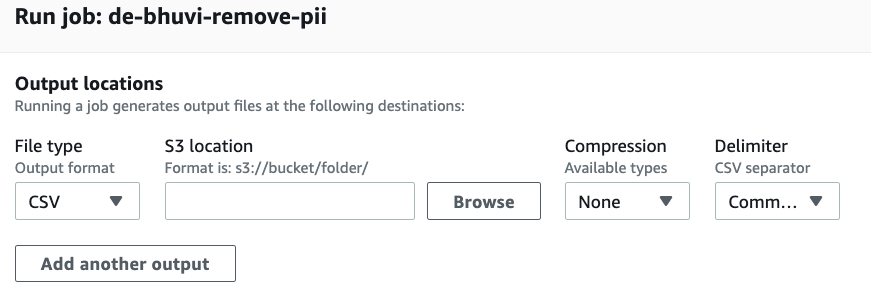
From the jobs tab, you can see the historical job execution.
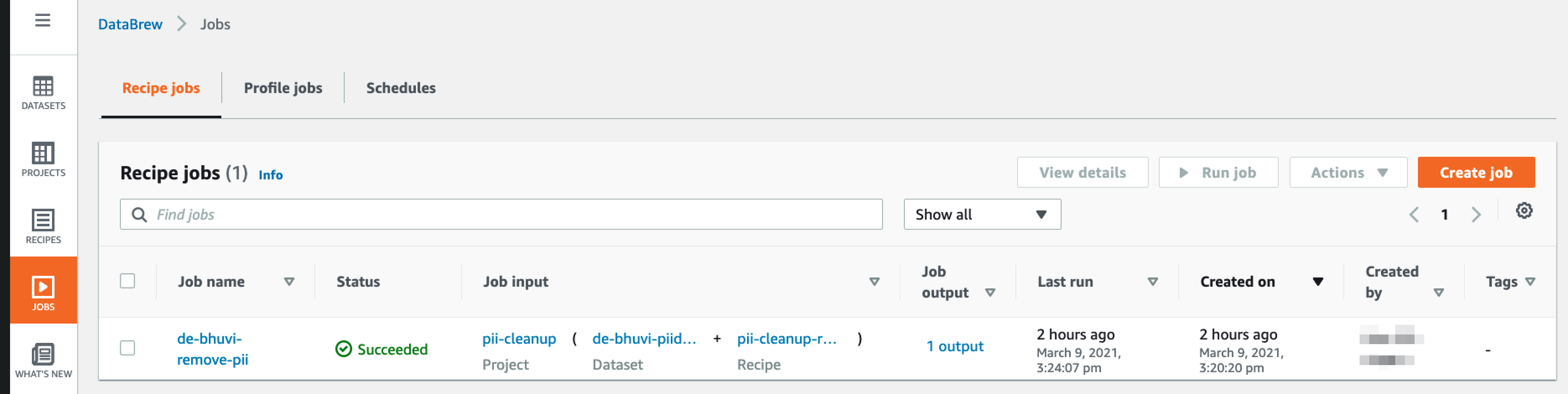
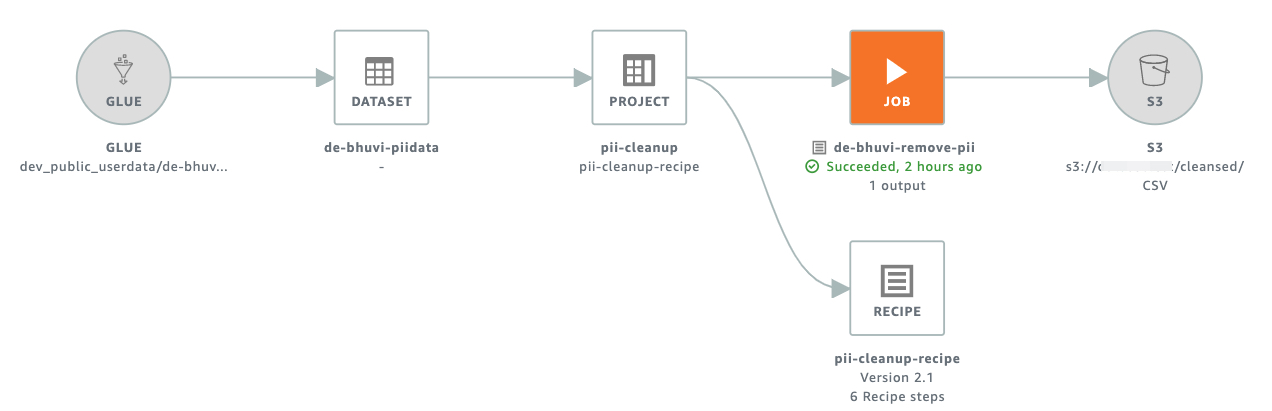
Concusion: #
This is a small PoC that we can use DataBrew for removing sensitive information, but it has more options to play with the data like Join multiple tables, make pivot tables and etc.
Gotchas: #
For sampling, DataBrew needs some data, so it’ll unload from RedShift to S3 and use it. This is expected behavior. But the unload process happened more than 3 times when I create the project.
Whenever the DataBrew project page refresh, then automatically an unload processing happening on the RedShift side. I don’t know the reason behind this.
Unfortunately, Brew outputs can send it to S3 only(for now). It may be a drawback for some users. But I think it’s not a big deal.
While saving the output into S3, the output file split into multiple small pieces even though the source data was too small. Is it due to parallelism or Glue’s behavior?