BackFill Failed Delivery From Kinesis To RedShift With Lambda
If you are dealing with the realtime data stream from Kinesis to RedShift, then you may face this situation where Redshift was down due to some maintenance activity and kinesis firehose was not able to ingest the data. But it has awesome features to retry after the next 60 Minutes. I had a situation that, there was a password change on the RedShift cluster on staging infra and we didn’t notice that the data load was failing. Now we need to backfill all those data into redshift using manifest files. One simple way, list all the files in errors manifest folders and generate the copy command and run those commands in loop or import as a .sql file. But I wanted to automate this process with lambda.
Why Lambda? #
I know it has 15mins of total runtime, but if you have fewer files then its good to use lambda. It’s serverless this is the only reason I choose lambda. Alternatively, you can use shell scripts with aws cli or any other language to process this.
Solution Overview: #
Lambda will put the failed deliveries manifest files in a directory called errors. The files are proper in a partitioned way error/manifest/yyyy/mm/dd/hh/
- Lambda should read all the manifest files for importing.(no manual process for mention the location every time)
- list-objects-v2 will not return more than 1000 files, so we used
paginateto loop this and get all the objects. - Redshift’s password is encrypted with KMS.
- Lambda needs
psychopg2to access Redshift, but the official version will not support redshift. We used a custom compiled version of psychopg2. - Once you imported the data with a manifest file, the next execution should not load the same file again and again. So we are moving the file once it’s imported.
- I’m a great fan of track everything into a metadata table. So every import process will be tracked along with what
COPYcommand it used.
Lambda Setup: #
- If you are thinking to launch lambda outside the VPC, then please don’t consider this blog.
- lambda needs to access KMS to decrypt the password. Its mandatory that the subnets which you are going to use launch the Lambda should have the NAT Gateway.
- Create a KMS key for the region where you are going to create this lambda function.
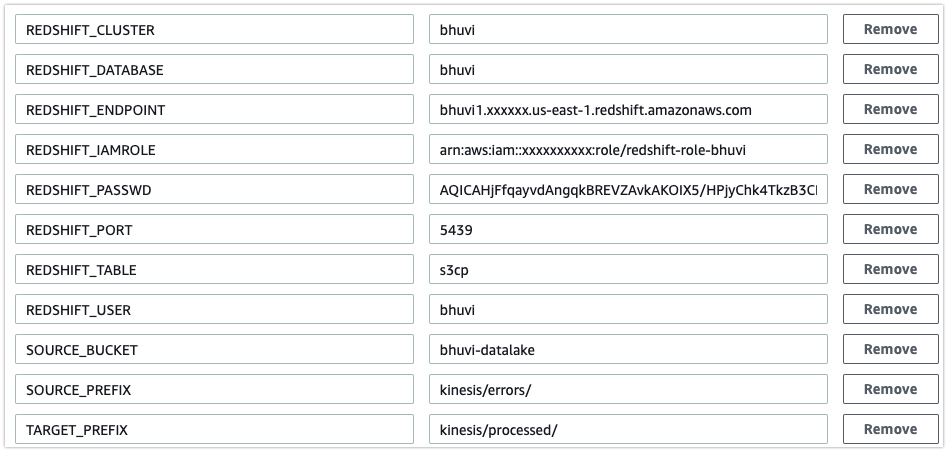
- Add the following variables in Lambda’s environment variables.
| Variable Name | Value |
|---|---|
| REDSHIFT_DATABASE | Your database name |
| REDSHIFT_TABLE | Your table name to import the data |
| REDSHIFT_USER | Redshift User Name |
| REDSHIFT_PASSWD | Redshift user’s password |
| REDSHIFT_PORT | Redshift port |
| REDSHIFT_ENDPOINT | Redshift Endpoint |
| REDSHIFT_IAMROLE | IAM role to access S3 inside Redshfit |
| SOURCE_BUCKET | Bucket name where you have the manifest file |
| SOURCE_PREFIX | Location of the error manifest files |
| TARGET_PREFIX | Location where to move the loaded manifest files |
- For this blog, I just encrypt the password only. Under encryption, configuration checks the
Enable helpers for encryption in transitandUse a customer master key. Choose the KMS key which you created for this. - Then you can see a button called
Encrypton all the environment variables. Just click encrypt on the password variable. - Lambda’s IAM role should have the predefined policy
AWSLambdaVPCAccessExecutionRole,AWSLambdaBasicExecutionRoleand one custom policy to access the KMS for decrypting it.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "kms:Decrypt",
"Resource": "<your-kms-arn>"
}
]
}- From the network choose the VPC and subnets(must be attached with NAT/NAT Gateway) and a security group where all traffic allowed to its own ID.
- Make sure the redshift cluster’s security group should accept the connections from the lambda subnet IP range.
128MBMemory fine for me, but this memory and the timeout can be configured as per your workload.
Code for the Function: #
import os
import boto3
import psycopg2
import sys
from base64 import b64decode
from datetime import datetime
s3 = boto3.client('s3')
kms = boto3.client('kms')
# Get values from Env
REDSHIFT_DATABASE = os.environ['REDSHIFT_DATABASE']
REDSHIFT_TABLE = os.environ['REDSHIFT_TABLE']
REDSHIFT_USER = os.environ['REDSHIFT_USER']
REDSHIFT_PASSWD = os.environ['REDSHIFT_PASSWD']
REDSHIFT_PORT = os.environ['REDSHIFT_PORT']
REDSHIFT_ENDPOINT = os.environ['REDSHIFT_ENDPOINT']
REDSHIFT_CLUSTER = os.environ['REDSHIFT_CLUSTER']
REDSHIFT_IAMROLE = os.environ['REDSHIFT_IAMROLE']
DE_PASS = kms.decrypt(CiphertextBlob=b64decode(REDSHIFT_PASSWD))['Plaintext']
# Declare other parameters
TRIGGER_TIME = str(datetime.now())
SOURCE_BUCKET = os.environ['SOURCE_BUCKET']
SOURCE_PREFIX = os.environ['SOURCE_PREFIX']
TARGET_PREFIX = os.environ['TARGET_PREFIX']
# Define the Functions
"""
Function 1: Get all manifest files
This fuction is written by alexwlchan
(https://alexwlchan.net/2019/07/listing-s3-keys/)
list_objects_v2 won't support more than 1000 files,
so it'll paginate to next 1000 and so on.
"""
def get_matching_s3_objects(bucket, prefix="", suffix=""):
paginator = s3.get_paginator("list_objects_v2")
kwargs = {'Bucket': bucket}
if isinstance(prefix, str):
prefixes = (prefix, )
else:
prefixes = prefix
for key_prefix in prefixes:
kwargs["Prefix"] = key_prefix
for page in paginator.paginate(**kwargs):
try:
contents = page["Contents"]
except KeyError:
return
for obj in contents:
key = obj["Key"]
if key.endswith(suffix):
yield obj
def get_matching_s3_keys(bucket, prefix="", suffix=""):
for obj in get_matching_s3_objects(bucket, prefix, suffix):
yield obj["Key"]
"""
Function 2: Connection string for RedShift
Its using a custom complied psycopg2
https://github.com/jkehler/awslambda-psycopg2
"""
def get_pg_con(
user=REDSHIFT_USER,
password=DE_PASS.decode("utf-8"),
host=REDSHIFT_ENDPOINT,
dbname=REDSHIFT_DATABASE,
port=REDSHIFT_PORT,
):
return psycopg2.connect(dbname=dbname,
host=host,
user=user,
password=password,
port=port)
"""
Function 3: Main function
"""
def run_handler(handler, context):
all_files = get_matching_s3_keys(SOURCE_BUCKET, SOURCE_PREFIX)
for file in all_files:
source_file = {'Bucket': SOURCE_BUCKET,'Key': file}
target_file = TARGET_PREFIX + str(file) + ".done"
print (SOURCE_BUCKET)
print (SOURCE_PREFIX)
print (file)
#Process starting here
start_time = str(datetime.now())
copy_command="COPY " + REDSHIFT_TABLE + " FROM 's3://" + SOURCE_BUCKET + "/" + file + "' iam_role '" + REDSHIFT_IAMROLE + "' MANIFEST json 'auto' GZIP;"
conn = get_pg_con()
cur = conn.cursor()
#print (copy_command) - For debug
cur.execute(copy_command)
#Insert to History Table
end_time = str(datetime.now())
history_insert="insert into error_copy_history (TRIGGER_TIME,start_time,end_time,db_name,table_name,file) values ( '" + TRIGGER_TIME + "','" + start_time + "','" + REDSHIFT_DATABASE + "','" + db_name + "','" + table_name + "','s3://floweraura-rawdata/" + file +"');"
cur.execute(history_insert)
#Commit and Close
conn.commit()
cur.close()
conn.close()
#Move the files from Errors directory to processed directory
s3.copy(source_file, SOURCE_BUCKET, target_file)
print ("copied", file)
s3.delete_object(Bucket=SOURCE_BUCKET,Key=file)
print ("deleted", file)How to Deploy it? #
As I mentioned above, you need to use the custom complied psychopg2 which you can download from the below link.
https://github.com/jkehler/awslambda-psycopg2
I’m using Python 3.6 on Lambda. So download this repo and rename the psycopg2-3.6 to psycopg2. And then create a file with name pgcode.py and paste the above python code.
Now create a zip file with the psycopg2 and pgcode.py upload this file to lambda. In the lambda Handler use pgcode.run_handler

That’s it, your lambda function is ready, not really ready to execute.
Create the History Table: #
To maintain this import process in a table, we need to create a table in RedShift.
CREATE TABLE error_copy_history
(
pid INT IDENTITY(1, 1),
trigger_time DATETIME,
start_time DATETIME,
end_time DATETIME,
db_name VARCHAR(100),
table_name VARCHAR(100),
FILE VARCHAR(65000)
); Run the Function: #
Im giving my s3 path and lambda environment variables here for your reference.
- S3 bucket -
bhuvi-datalakeHere Im storing all the kinesis data. - S3 prefix -
kinesis/errors/Failed manifest files will go to this path (eg:kinesis/errors/2019/10/21/13/ - Target prefix -
kinesis/processed/Once the data imported to Redshift the loaded manifest file will go to this location.
Once the execution was done, you can see the load history from the History table.
bhuvi=# select * from error_copy_history limit 1;
pid | 260
trigger_time | 2019-10-17 08:14:23.495213
start_time | 2019-10-17 08:14:24.59309
end_time | 2019-10-17 08:14:24.917248
db_name | bhuvi
table_name | s3cp
file | s3://bhuvi-datalake/errors/manifests/2019/09/26/13/collect-redshift-2019-09-26-13-21-49-56371982-2375-4b28-8d79-45f01952667eFurther Customization: #
- I ran this on Ad-Hoc basis, but if you want to run this automatically, then use Cloudwatch triggers to trigger this on daily or any N internal.
- I used KMS for encrypting the password, you can use IAM temporary credentials also.
- My S3 data is compressed and JSON format. If you have different file format and compression then modify your COPY command in the python code.