Debezium MySQL Snapshot For AWS RDS Aurora From Backup Snaphot
I have published enough Debezium MySQL connector tutorials for taking snapshots from Read Replica. To continue my research I wanted to do something for AWS RDS Aurora as well. But aurora is not using binlog bases replication. So we can’t use the list of tutorials that I published already. In Aurora, we can get the binlog file name and its position from its snapshot of the source Cluster. So I used a snapshot for loading the historical data, and once it’s loaded we can resume the CDC from the main cluster.
Requirements: #
- Running aurora cluster.
- Aurora cluster must have binlogs enabled.
- Make binlog retention period to a minimum 3 days(its a best practice).
- Debezium connector should be able to access both the clusters.
- Make sure you have different security groups for the main RDS Aurora cluster and the Snapshot cluster.
Sample data in source aurora: #
create database bhuvi;
use bhuvi;
create table rohi (
id int,
fn varchar(10),
ln varchar(10),
phone int);
insert into rohi values (1, 'rohit', 'last',87611);
insert into rohi values (2, 'rohit', 'last',87611);
insert into rohi values (3, 'rohit', 'last',87611);
insert into rohi values (4, 'rohit', 'last',87611);
insert into rohi values (5, 'rohit', 'last',87611);Take Aurora snapshot: #
Go to the RDS console and select your source Aurora master node. Take a snapshot of it. Once the snapshot has been done, you see that in the snapshots tab.

New cluster from snapshot: #
Then create a new cluster from the snapshot. Once its launched, we can get the binlog info from the logs.
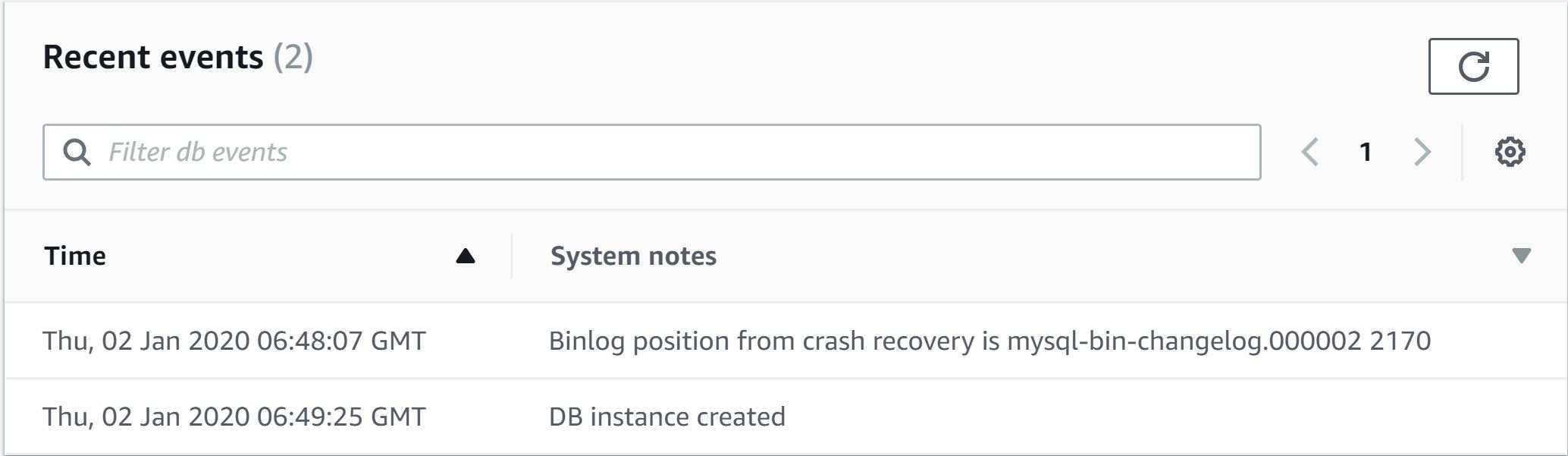
In RDS Console, select the instance name. Click on the Logs & Events tab. Below the Recent events, you can see the binlog information of the source Aurora node while talking the snapshot. This cluster also needs to enable with binlog.
Register the MySQL Connector: #
Follow this link to configure Kafka cluster and connector. Create a file called mysql.json and add the Snapshot cluster’s information.
{
"name": "mysql-connector-db01",
"config": {
"name": "mysql-connector-db01",
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.server.id": "1",
"tasks.max": "1",
"database.history.kafka.bootstrap.servers": "YOUR-BOOTSTRAP-SERVER:9092",
"database.history.kafka.topic": "schema-changes.mysql",
"database.server.name": "mysql-db01",
"database.hostname": "SNAPSHOT-INSTANCE-ENDPOINT",
"database.port": "3306",
"database.user": "bhuvi",
"database.password": "****",
"database.whitelist": "bhuvi",
"snapshot.mode": "initial",
"snapshot.locking.mode": "none",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"internal.key.converter": "org.apache.kafka.connect.json.JsonConverter",
"internal.value.converter": "org.apache.kafka.connect.json.JsonConverter",
"internal.key.converter.schemas.enable": "false",
"internal.value.converter.schemas.enable": "false",
"transforms": "unwrap",
"transforms.unwrap.add.source.fields": "ts_ms",
"tombstones.on.delete": "false",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
}
}Run the below command to register it on the connector node.
curl -X POST -H "Accept: application/json" -H "Content-Type: application/json" http://localhost:8083/connectors -d @mysql.jsonOnce the snapshot has been done, you can see the snapshot cluster’s current binlog file name and its position in the connect-offsets topic.
kafka-console-consumer --bootstrap-server localhost:9092 --topic connect-offsets --from-beginning
{"file":"mysql-bin-changelog.000006","pos":154}Add more data on the source Cluster: #
To simulate the real production setup, add few more rows to the rohi table.
insert into rohi values (6, 'rohit', 'last',87611);
insert into rohi values (7, 'rohit', 'last',87611);Also, create a new table.
use bhuvi;
create table testtbl (id int);
insert into testtbl values (1);Because, once we switch to the source cluster, it should read these new data.
Update the Source Aurora binlog info: #
Stop the connector service and manually inject the binlog information that we got from the Snapshot cluster’s Log & Events section.
connector-node# systemctl stop confluent-connect-distributedGet the last read binlog information and its parition from the connect-offsets topic.
kafkacat -b localhost:9092 -C -t connect-offsets -f 'Partition(%p) %k %s\n'
Partition(0) ["mysql-connector-db01",{"server":"mysql-db01"}] {"file":"mysql-bin-changelog.000006","pos":154}kafkacat- command-line utility from confluent.-b localhost:9092- broker details-C- Consumer-t connect-offsets- topicPartition(0)- The partition name where we have the binlog info.mysql-connector-db01- connector name"server":"mysql-db01- server name we used inmysql.jsonfile
Run the following command to inject the binlog info to the connect-offsets topic.
echo '["mysql-connector-db01",{"server":"mysql-db01"}]|{"file":"mysql-bin-changelog.000002","pos":2170}' | \
kafkacat -P -b localhost:9092 -t connect-offsets -K\ | -p 0mysql-connector-db01- connector name"server":"mysql-db01- server name we used inmysql.jsonfile{"file":"mysql-bin-changelog.000002","pos":2170}- Binlog info from the snapshot cluster’s log.kafkacat- command-line utility from confluent.-P- Producer-b localhost:9092- broker details-t connect-offsets- topic-p 0Partition where we have the binlog info.
Now if you read the data from the consumer, it’ll show the new binlog.
kafka-console-consumer --bootstrap-server localhost:9092 --topic connect-offsets --from-beginning
{"file":"mysql-bin-changelog.000006","pos":154}
{"file":"mysql-bin-changelog.000002","pos":2170}Switch to Source Cluster: #
Before doing the switchover, we need to make that the connector should not access to the snapshot cluster once the connector service started. We can achieve this in 2 ways.
- Anyhow, we read all the from the snapshot cluster, so delete it.
- In the Snapshot cluster’s security group, remove the connector’s node IP.
I recommend using the 2nd option. Now start the connector service. After a few seconds, you can see the logs like below.
\[2020-01-02 06:57:21,448\] INFO Starting MySqlConnectorTask with configuration: (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,450\] INFO connector.class = io.debezium.connector.mysql.MySqlConnector (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,450\] INFO snapshot.locking.mode = none (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,451\] INFO tasks.max = 1 (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,451\] INFO database.history.kafka.topic = replica-schema-changes.mysql (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,452\] INFO transforms = unwrap (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,452\] INFO internal.key.converter.schemas.enable = false (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,452\] INFO transforms.unwrap.add.source.fields = ts_ms (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO tombstones.on.delete = false (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO transforms.unwrap.type = io.debezium.transforms.ExtractNewRecordState (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO value.converter = org.apache.kafka.connect.json.JsonConverter (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO database.whitelist = bhuvi (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO key.converter = org.apache.kafka.connect.json.JsonConverter (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO database.user = admin (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO database.server.id = 1 (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO database.history.kafka.bootstrap.servers = 172.31.40.132:9092 (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO database.server.name = mysql-db01 (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,453\] INFO database.port = 3306 (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO key.converter.schemas.enable = false (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO internal.key.converter = org.apache.kafka.connect.json.JsonConverter (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO task.class = io.debezium.connector.mysql.MySqlConnectorTask (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO database.hostname = snapshot-cluster.cluster-chbcar19iy5o.us-east-1.rds.amazonaws.com (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO database.password = ******** (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO internal.value.converter.schemas.enable = false (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO name = mysql-connector-db01 (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO value.converter.schemas.enable = false (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO internal.value.converter = org.apache.kafka.connect.json.JsonConverter (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,454\] INFO snapshot.mode = initial (io.debezium.connector.common.BaseSourceTask)
\[2020-01-02 06:57:21,512\] INFO \[Producer clientId=connector-producer-mysql-connector-db01-0\] Cluster ID: H-jsdNk9SUuud35n3AIk8g (org.apache.kafka.clients.Metadata)Update the Endpoint: #
Create an updated config file which has the endpoint of Source Aurora endpoint and the snapshot mode = schema only recovery .
And the main important thing is use a different topic for schema changes history. Else you’ll end up with some error like below.
ERROR Failed due to error: Error processing binlog event (io.debezium.connector.mysql.BinlogReader)
org.apache.kafka.connect.errors.ConnectException: Encountered change event for table bhuvi.rohi whose schema isn't known to this connectorFile: mysql-update.json
{
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"snapshot.locking.mode": "none",
"tasks.max": "3",
"database.history.kafka.topic": "schema-changes.mysql",
"transforms": "unwrap",
"internal.key.converter.schemas.enable": "false",
"transforms.unwrap.add.source.fields": "ts_ms",
"tombstones.on.delete": "false",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"database.whitelist": "bhuvi",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"database.user": "admin",
"database.server.id": "1",
"database.history.kafka.bootstrap.servers": "BROKER-NODE-IP:9092",
"database.server.name": "mysql-db01",
"database.port": "3306",
"key.converter.schemas.enable": "false",
"internal.key.converter": "org.apache.kafka.connect.json.JsonConverter",
"database.hostname": "SOURCE-AURORA-ENDPOINT",
"database.password": "*****",
"internal.value.converter.schemas.enable": "false",
"name": "mysql-connector-db01",
"value.converter.schemas.enable": "false",
"internal.value.converter": "org.apache.kafka.connect.json.JsonConverter",
"snapshot.mode": "SCHEMA_ONLY_RECOVERY"
}Run the below command to update the MySQL connector.
curl -X PUT -H "Accept: application/json" -H "Content-Type: application/json" http://localhost:8083/connectors/mysql-connector-db01/config -d @mysql-update.jsonThen immediately it’ll start reading from the Source Aurora cluster from the binlog position mysql-bin-changelog.000002 2170
You can see these changes from the connect-offsets topic.
kafka-console-consumer --bootstrap-server localhost:9092 --topic connect-offsets --from-beginning
{"file":"mysql-bin-changelog.000006","pos":154}
{"file":"mysql-bin-changelog.000002","pos":2170}
{"ts_sec":1577948351,"file":"mysql-bin-changelog.000003","pos":1207,"row":1,"server_id":2115919109,"event":2}And we add 2 more rows to the rohi table. You can see those new values from the bhuvi.rohi topic.
kafka-console-consumer --bootstrap-server localhost:9092 --topic mysql-db01.bhuvi.rohi --from-beginning
{"id":1,"fn":"rohit","ln":"last","phone":87611,"__ts_ms":0}
{"id":2,"fn":"rohit","ln":"last","phone":87611,"__ts_ms":0}
{"id":3,"fn":"rohit","ln":"last","phone":87611,"__ts_ms":0}
{"id":4,"fn":"rohit","ln":"last","phone":87611,"__ts_ms":0}
{"id":5,"fn":"rohit","ln":"last","phone":87611,"__ts_ms":0}
{"id":6,"fn":"rohit","ln":"last","phone":87611,"__ts_ms":1577948298000}
{"id":7,"fn":"rohit","ln":"last","phone":87611,"__ts_ms":1577948304000}Also, you can the new table testtbl added to the topic.
kafka-topics --zookeeper localhost:2181 --list
connect-configs
connect-offsets
connect-status
default_ksql_processing_log
mysql-db01
mysql-db01.bhuvi.rohi
mysql-db01.bhuvi.testtbl
replica-schema-changes.mysql
schema-changes.mysqlDebezium Series blogs: #
- Build Production Grade Debezium Cluster With Confluent Kafka
- Monitor Debezium MySQL Connector With Prometheus And Grafana
- Debezium MySQL Snapshot From Read Replica With GTID
- Debezium MySQL Snapshot From Read Replica And Resume From Master
- Debezium MySQL Snapshot For AWS RDS Aurora From Backup Snaphot
- RealTime CDC From MySQL Using AWS MSK With Debezium