GCP Convert StackDriver Log Sink As Hive Partition In GCS
GCP StackDriver Logs can be exported to GCS and BigQuery as well. The data export on GCS will be a clean directory structure. It’ll be like gs://bucket/prefix/yyyy/mm/dd/file. Its looks good. Recently we were working on some application log sink from multiple VMs to GCS via StackDriver agent. So the logs first pushed to StackDriver logging then we created a sink to GCS bucket. But later we got a new requirement that sometimes the app developers want to see the data for a particular date. Unfortunately, the current directory structure will not help us to do this. As per BigQuery’s Hive partition format, we need to keep the directory structure with directory-name=somevalue. Also in stackdriver sink we can’t make this change. So decided to make this change when the file arrives at the GCS bucket.
The file processing flow: #
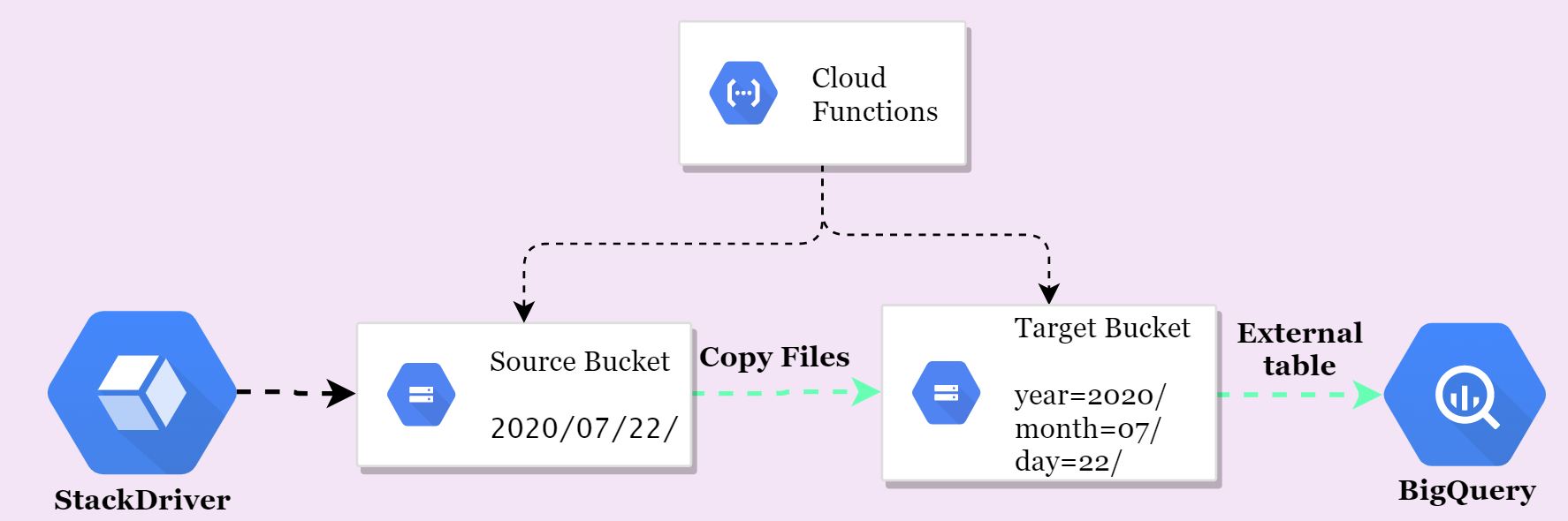
- When the Stackdriver sink push the log file to GCS storage, then we can trigger the cloud function.
- The Cloud function will get the file name(full path from the prefix)
- Extract the YYY, MM, and DD from the path.
- Then COPY the file from the Source bucket to Target bucket.
- Delete file from the Source bucket(Optional)
Create the Cloud Function:(Python 3.8) #
Requirements: #
- Service account with GCS Admin access to perform the COPY and Delete processes.
- Python 3.7 or 3.8
- Trigger: Cloud Storage
- Event Type: Finalize/Create
Code: #
from google.cloud import storage
def hello_gcs_generic(data, context):
sourcebucket=format(data['bucket'])
source_file=format(data['name'])
year = source_file.split("/")[1]
month = source_file.split("/")[2]
day = source_file.split("/")[3]
filename=source_file.split("/")[4]
targetbucket = 'target-bucket'
storage_client = storage.Client()
source_bucket = storage_client.bucket(sourcebucket)
source_blob = source_bucket.blob(source_file)
destination_bucket = storage_client.bucket(targetbucket)
destination_blob_name = 'hivelog/year='+year+'/month='+month+'/day='+day+'/'+filename
blob_copy = source_bucket.copy_blob(
source_blob, destination_bucket, destination_blob_name
)
# Delete Optional
bucket = storage_client.bucket(sourcebucket)
blob = bucket.blob(source_file)
blob.delete()
print(
"Blob {} in bucket {} copied to blob {} in bucket {}.".format(
source_blob.name,
source_bucket.name,
blob_copy.name,
destination_bucket.name,
)
)
Note: Our file path is gs://bucket/logdirname/2020/07/22/file.json. So while using split command to extract the year we used 1, and month 2 then day is 3, logdirname is 0. And replace the target bucket name(
targetbucket).
requirements.txt #
google-cloud-storage
Testing time: #
Install gcloud SDK on your computer and start uploading some random files.
gsutil cp MOCK_DATA.json gs://source-bucket/bhuvi-test/2020/07/19/
gsutil cp MOCK_DATA.json gs://source-bucket/bhuvi-test/2020/07/20/
Let see data on the target bucket.
gsutil ls gs://target-bucket/hivelog/
gs://target-bucket/hivelog/year=2020/
gsutil ls gs://target-bucket/hivelog/year=2020/month=07/day=20/
gs://target-bucket/hivelog/year=2020/month=07/day=20/MOCK_DATA.json
BigQuery External Table: #
Now we can create a BigQuery external table with partition.
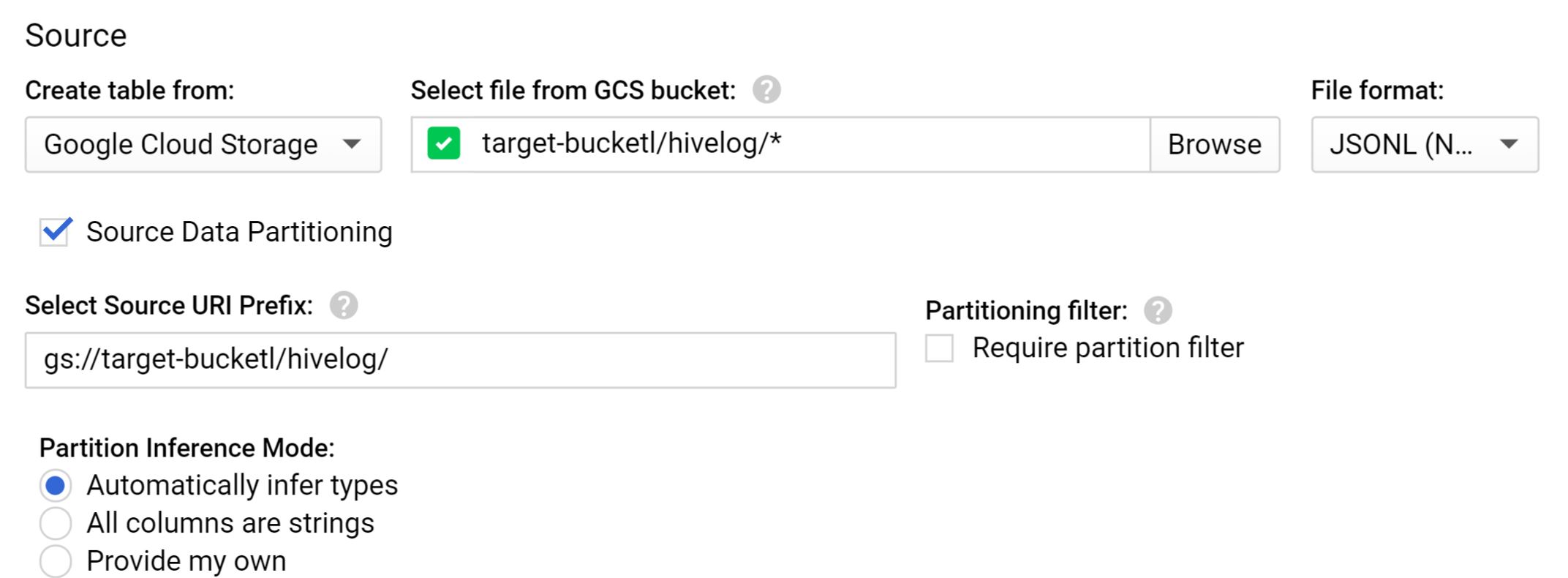
I have 2 files from two different dates. Each file has 1000 lines. Lets query the data and see the Hive partition is working or not.
SELECT count(*) FROM `mydataset-bqtbl`;
2000
SELECT count(*) FROM `mydataset-bqtbl` where year=2020;
2000
SELECT count(*) FROM `mydataset-bqtbl` where day=20;
1000
Yes, we got the expected results. This is just with a small number of files. But when we deployed this for the StackDriver logs, we could see the better performance with less cost.
What will happen if we COPY from same bucket: #
You may think like use the source and target buckets as same, but the prefix is different? We tried it and see what happened?
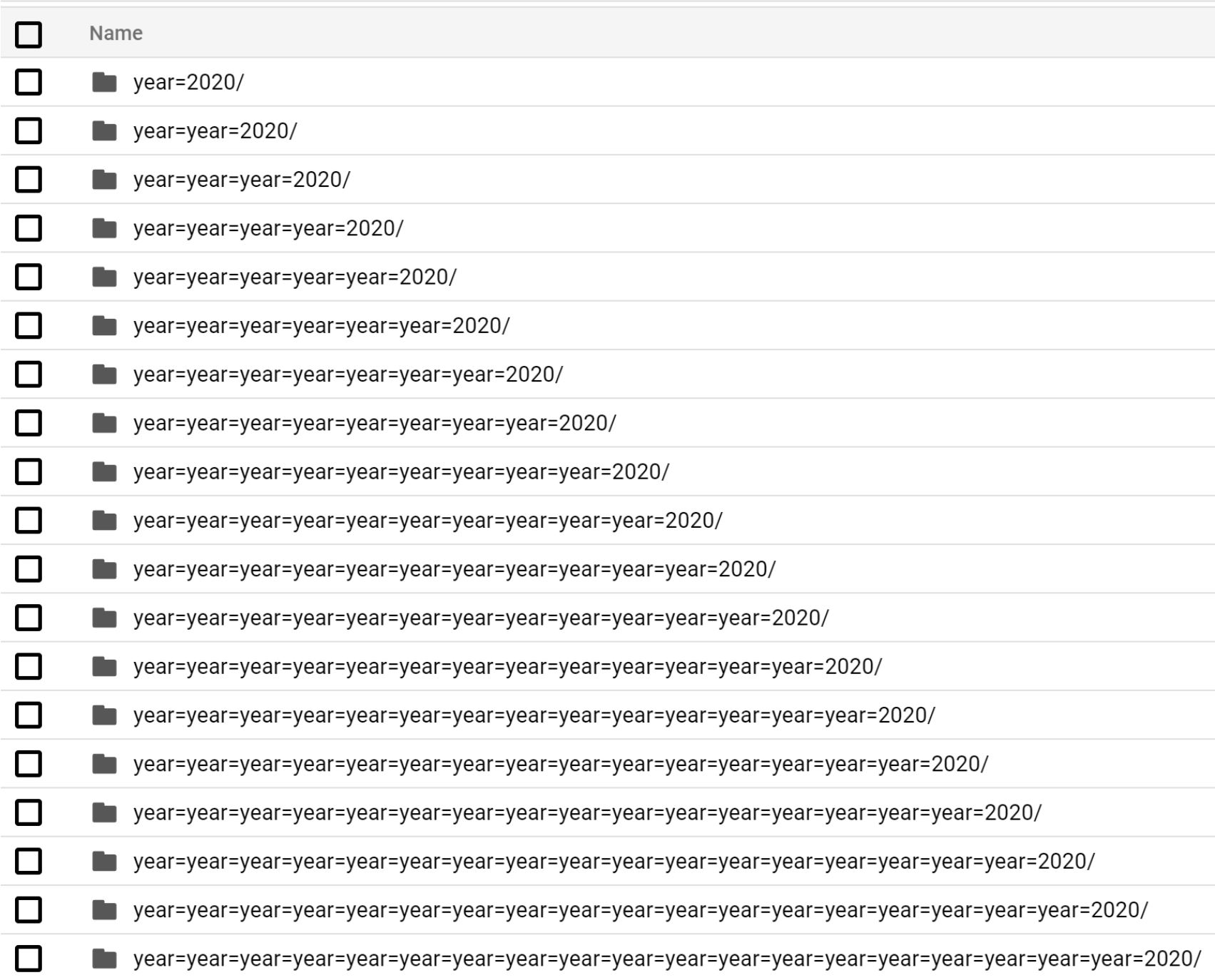 The first source file generated the paition with year=2020/
then that Partitioned file created one more Partition like year=year=2020 then again one more for this, the loop is infinite.
The first source file generated the paition with year=2020/
then that Partitioned file created one more Partition like year=year=2020 then again one more for this, the loop is infinite.
A special thanks to Dustin Ingram who helped me to figure this out.
Unfortunatly in GCP, we don’t have control on filter the some prefix based triggers. So if you want to use this, the source and the target buckets must be different.