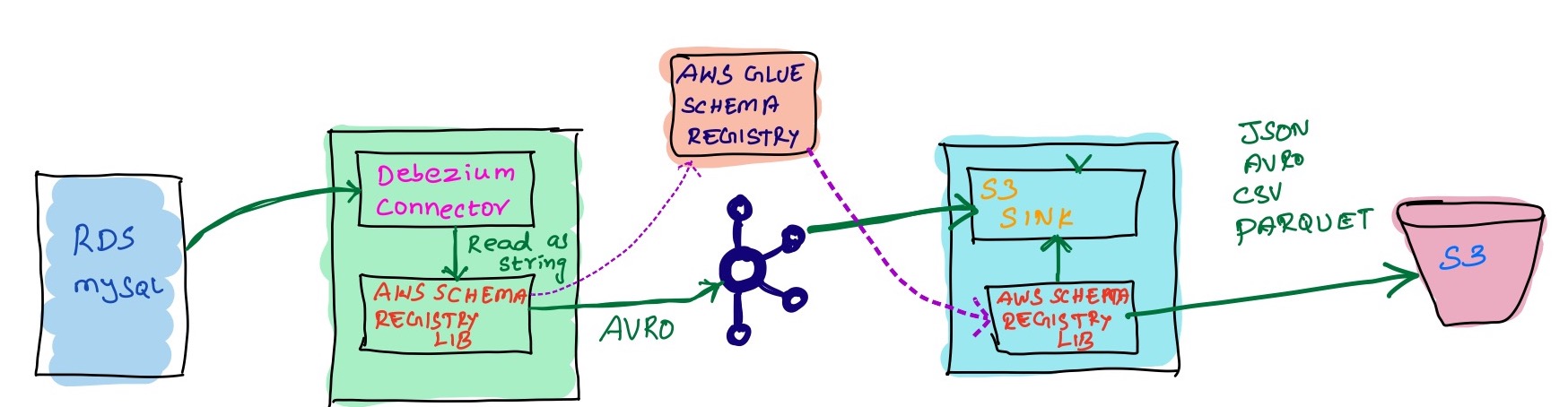
Integrate Debezium And Sink Connectors With AWS Glue Schema Registry
AWS Glue Schema Registry is providing the schema registry for streaming platforms like Kafka, AWS MSK, Kinesis and etc. If you are on the AWS ecosystem and planning to build something like a DataLake or LakeHouse, then a centralized repository for your schema registry is very important and it’ll simplify the whole process by having a single point of contact. Even I had a similar scenario where I need to integrate the Debezium connecter with the AWS schema registry. We are planning to leverage LakeHouse, DataLake, and maybe DataMesh in the future. So we would like to have a single repo for the schema registry that will fit into the AWS ecosystem. As a part of this, we wanted to add Debezium with the Glue Schema Registry.
NOTE: AWS documentation has a section for the Kafka connect integration, but those steps are not working, and if you are a newbie to Kafka, then it may be difficult to understand that.
Integration: #
AWS schema registry doesn’t natively support by any other Kafka connect. We have to add the AWS Schema Registry libraries to the Kafka workers and then add the properties to the respective connectors. This library is completely opensource and provides support for storing the schema in Avro, JSON, and Protopuf format.
Let’s do the integration by compiling the AWS schema registry library. Make sure you have Java version 1.8 or later.
cd /opt
git clone https://github.com/awslabs/aws-glue-schema-registry.git
cd aws-glue-schema-registry/
mvn clean install
mvn dependency:copy-dependencies
Add this jar’s location(/opt/aws-glue-schema-registry) into the Kafka worker properties(on all the nodes) and restart the service, Im using it in distributed mode.
vi /etc/kafka/connect-distributed.properties plugin.path=/usr/share/java,/usr/share/confluent-hub-components,/opt/aws-glue-schema-registry
Pre-Requisites: #
- The debezium connectors are running on EC2 instances, so to connect with the AWS Schema registry, the lib can use the Instance Role. So we need an EC2 IAM Role with the following permissions Or simply add the
AWSGlueSchemaRegistryFullAccesspolicy.
Replace
XXX_AWS_ACC_NO_XXXwith your AWS account number.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:ListSchemaVersions",
"glue:GetRegistry",
"glue:GetSchemaVersion",
"glue:QuerySchemaVersionMetadata",
"glue:GetSchemaVersionsDiff",
"glue:ListSchemas",
"glue:ListRegistries",
"glue:GetSchema",
"glue:GetSchemaByDefinition"
],
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"glue:CreateRegistry",
"glue:RegisterSchemaVersion",
"glue:DeleteSchema",
"glue:UpdateRegistry",
"glue:RemoveSchemaVersionMetadata",
"glue:CreateSchema",
"glue:UpdateSchema",
"glue:DeleteSchemaVersions",
"glue:DeleteRegistry"
],
"Resource": [
"arn:aws:glue:*:XXX_AWS_ACC_NO_XXX:registry/*",
"arn:aws:glue:*:XXX_AWS_ACC_NO_XXX:schema/*"
]
}
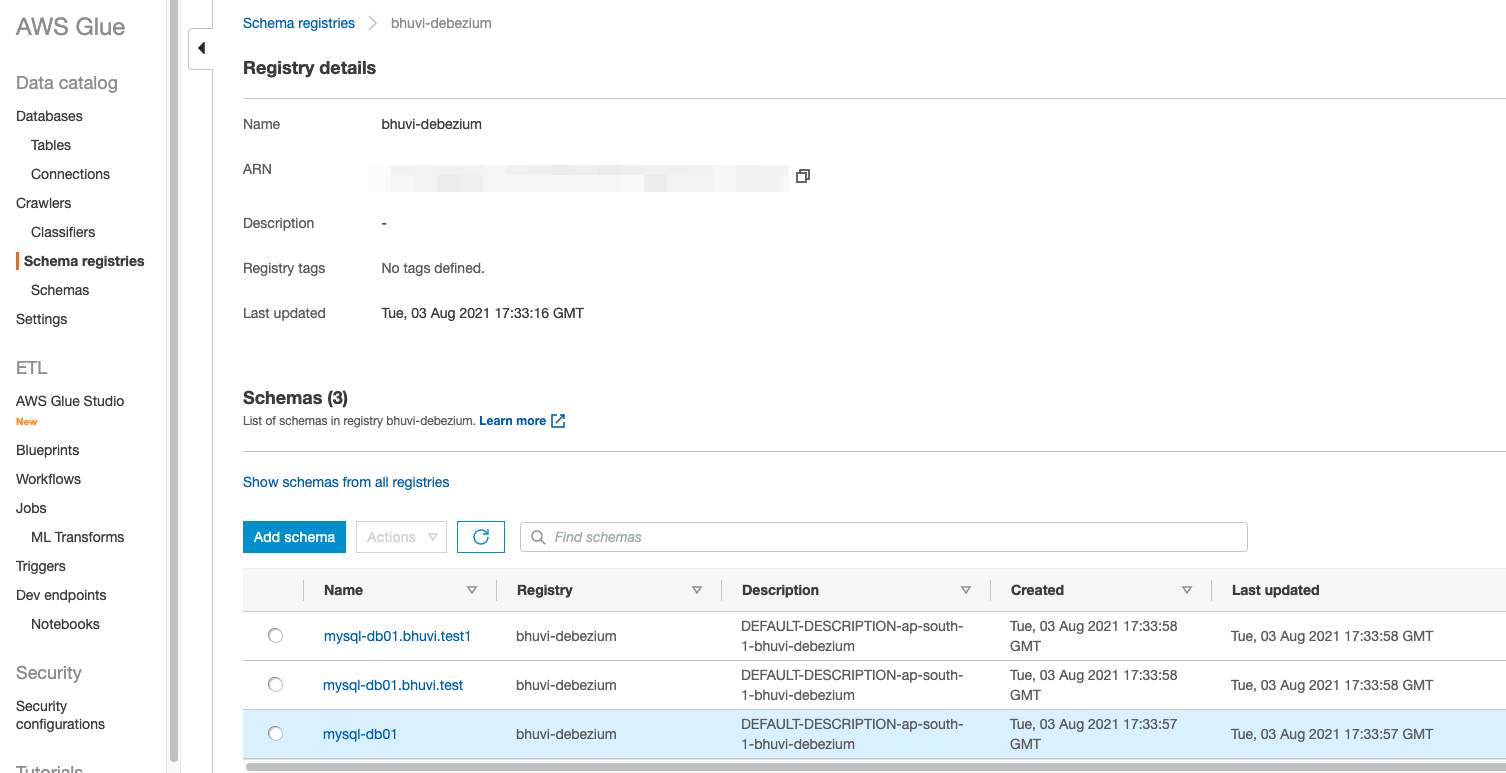
- I want to put all the schema into a registry called
bhuvi-debezium, we have to create this registry manually on the Glue schema registry.
Avro Format: #
Now, let’s create a Debezium connecter config file with the following properties.
Filename: mysql-config.json
Please replace the Kafka broker and MySQL details.
{
"name": "mysql-connecter-01",
"config": {
"name": "mysql-connecter-01",
"connecter.class": "io.debezium.connecter.mysql.MySqlconnecter",
"database.server.id": "1",
"tasks.max": "1",
"database.history.kafka.bootstrap.servers": "KAFKA_BROKER_NODE_IP:9092",
"database.history.kafka.topic": "mysql-db01.schema-changes.mysql",
"database.server.name": "mysql-db01",
"database.hostname": "MYSQL_IP",
"database.port": "3306",
"database.user": "MYSQL_USER",
"database.password": "MYSQL_PASS",
"database.whitelist": "bhuvi",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.add.source.fields": "ts_ms",
"tombstones.on.delete": false,
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"internal.key.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter",
"internal.key.converter.schemas.enable": "false",
"internal.value.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter",
"internal.value.converter.schemas.enable": "false",
"value.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter",
"value.converter.schemas.enable": "true",
"value.converter.region": "ap-south-1",
"key.converter.schemaAutoRegistrationEnabled": "true",
"value.converter.schemaAutoRegistrationEnabled": "true",
"key.converter.avroRecordType": "GENERIC_RECORD",
"value.converter.avroRecordType": "GENERIC_RECORD",
"key.converter.registry.name": "bhuvi-debezium",
"value.converter.registry.name": "bhuvi-debezium",
"snapshot.mode": "initial"
}
}
Deploy the connecter: #
curl -X POST -H "Accept: application/json" -H "Content-Type: application/json" http://localhost:8083/connectors -d @mysql-config.json
Checking the status: #
curl GET localhost:8083/connectors/mysql-connecter-01/status | jq
{
"name": "mysql-connecter-01",
"connecter": {
"state": "RUNNING",
"worker_id": "172.30.32.13:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "172.30.32.13:8083"
}
],
"type": "source"
}
AWS Glue schema registry: #
Now we can go to the Glue schema registry, and under the schema’s we can see the schema for all the Kafka topics created by the Debezium(except the schema changes topic - which is not required)
Using JSON Format: #
We can use the same connecter config file to write the schema into the Glue schema registry in JSON by changing the KEY and Value Converters.
-- Add Debezium parameters as per the above config
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"internal.key.converter": "org.apache.kafka.connect.json.JsonConverter",
"internal.key.converter.schemas.enable": "false",
"internal.value.converter": "org.apache.kafka.connect.json.JsonConverter",
"internal.value.converter.schemas.enable": "false",
"value.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.jsonschema.JsonSchemaConverter",
"value.converter.schemas.enable": "true",
"value.converter.region": "ap-south-1",
"value.converter.schemaAutoRegistrationEnabled": "true",
"value.converter.avroRecordType": "GENERIC_RECORD",
"value.converter.dataFormat": "JSON",
"key.converter.registry.name": "bhuvi-debezium",
"value.converter.registry.name": "bhuvi-debezium",
Sink connectors: #
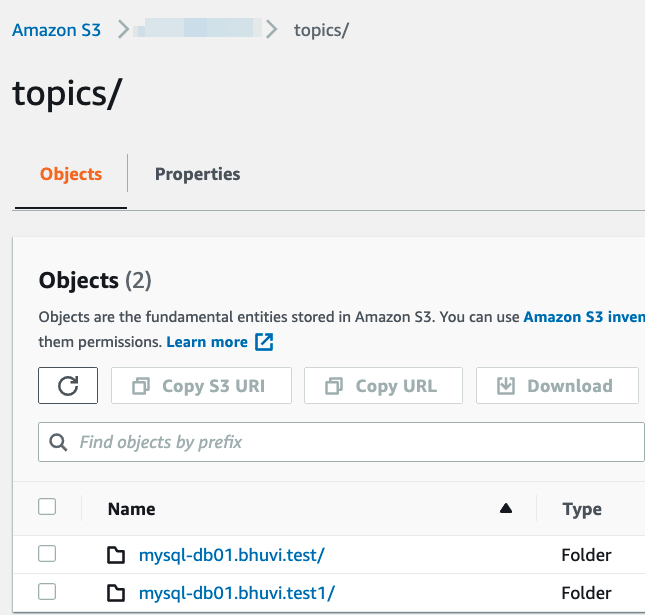
Now if you want to consume the data from the kafka and want to use the AWS Glue schema registry to get the schema, then the process is the same as the debezium config. In this blog, Im using the S3 Sink connecter to get the schema from the AWS glue schema registry(The schema from the producer side created with Avro format).
{
"name": "s3-sink-db01",
"config": {
"connecter.class": "io.confluent.connect.s3.S3Sinkconnecter",
"storage.class": "io.confluent.connect.s3.storage.S3Storage",
"s3.bucket.name": "S3_BUCKET",
"name": "s3-sink-db01",
"tasks.max": "3",
"s3.region": "ap-south-1",
"s3.part.size": "5242880",
"s3.compression.type": "gzip",
"timezone": "UTC",
"locale": "en",
"flush.size": "10",
"rotate.interval.ms": "10",
"topics.regex": "mysql-db01.(.*)",
"format.class": "io.confluent.connect.s3.format.json.JsonFormat ",
"partitioner.class": "io.confluent.connect.storage.partitioner.HourlyPartitioner",
"path.format": "YYYY/MM/dd/HH",
"partition.duration.ms": "3600000",
"errors.tolerance": "all",
"rotate.schedule.interval.ms": "3600000",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"internal.key.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter",
"internal.key.converter.schemas.enable": "false",
"internal.value.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter",
"internal.value.converter.schemas.enable": "false",
"value.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter",
"value.converter.schemas.enable": "true",
"value.converter.region": "ap-south-1",
"key.converter.schemaAutoRegistrationEnabled": "true",
"value.converter.schemaAutoRegistrationEnabled": "true",
"key.converter.avroRecordType": "GENERIC_RECORD",
"value.converter.avroRecordType": "GENERIC_RECORD",
"key.converter.registry.name": "bhuvi-debezium",
"value.converter.registry.name": "bhuvi-debezium"
}
}
If you want to read the JSON Format from Glue, then use the following configurations.
-- Add S3 sink connecter parameters as per the above config
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"internal.key.converter": "org.apache.kafka.connect.json.JsonConverter",
"internal.key.converter.schemas.enable": "false",
"internal.value.converter": "org.apache.kafka.connect.json.JsonConverter",
"internal.value.converter.schemas.enable": "false",
"value.converter": "com.amazonaws.services.schemaregistry.kafkaconnect.jsonschema.JsonSchemaConverter",
"value.converter.schemas.enable": "true",
"value.converter.region": "ap-south-1",
"value.converter.schemaAutoRegistrationEnabled": "true",
"value.converter.avroRecordType": "GENERIC_RECORD",
"value.converter.dataFormat": "JSON",
"key.converter.registry.name": "bhuvi-debezium",
"value.converter.registry.name": "bhuvi-debezium",
Things to remember: #
- Here Im using the
key.converterasStringConverter. I tried to use Avo and JSON directly there, but it was giving some errors and creating the schema 2 times. 1st with the Key and 2nd time with the value(Kafka records are in the key-value pair format). - If you already deployed a connecter and using the Avro format, then re-deploy the connecter with JSON format will give the error, so you need to delete the Schema from the schema registry.
- You can do more customizations like setting a description, buffer, TTL to cache the schema in the connector and etc. You can get all those flags Here