Internals Of Google DataStore And Technical Overview
Google Cloud Platform provides many varieties of solutions. In Data world particularly in NoSQL technology Google provides Datastore a highly scalable and availability solution with ACID capabilities. I have read a lot about the Google Datastore and its Internals. Here Im going to merge everything as a single blog post.

What / Why Datastore? #
Google datastore is a NoSQL database service. It can scale to multi regions. We should use Datastore as a Transactional Database. We shouldn’t use this for an Analytical purpose instead use BigTable is for OLAP.
- No need to provision and manage the Infra.
- No need for a DBA (performance, backup and restore, HA, Import and export).
- Fully Managed Service.
- ACID support.
- Highly scalable to multiple regions with very less latency.
- Highly Available.
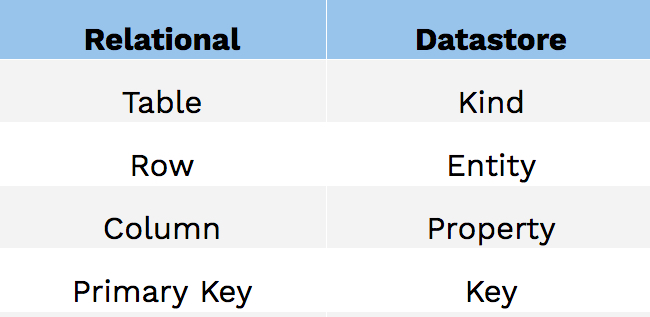
Relational vs Datastore #
Internals of Datastore: #
The Datastore is build on top the Google BigTable. So before understanding the Datastore lets understand the concept of the BigTable.
Google BigTable: #
Google Bigtable is a not a complete database, its a Storage for the data.
- BigTable is Used by Google internally since 2005.
- It’s a structured key-value storge.
- Distributed Storage.
- Highly available and scalable system.
- It supports CRUD (Create, Read, Update and Delete).
- BigTable only supports Range Scan.
- A Row contains a Key and Column.
- Data is sorted by Key (lexical order)
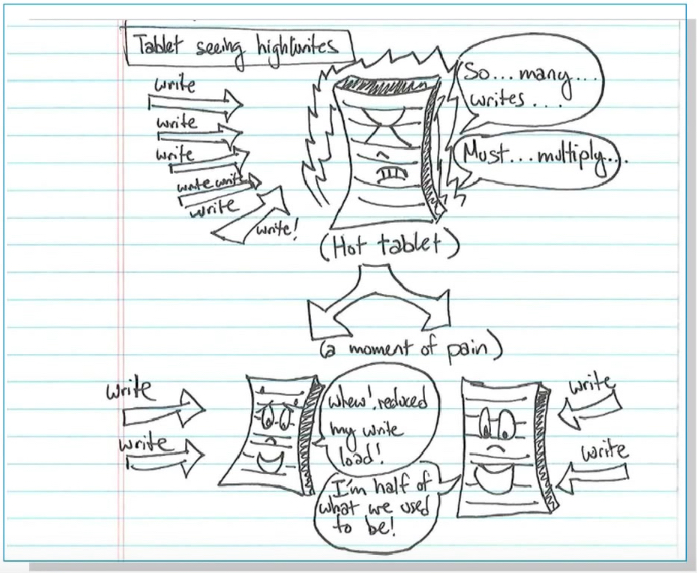
Auto sharding (Credits: google Next)
Datastore: #
All the BigTable capabilities are suitable for Datastore as well. Because Datastore is built on top of it. Google came up with a solution as Datastore to make the BigTable as a NoSQL Transactional Database. See the below image, all of these things are managed by Google.
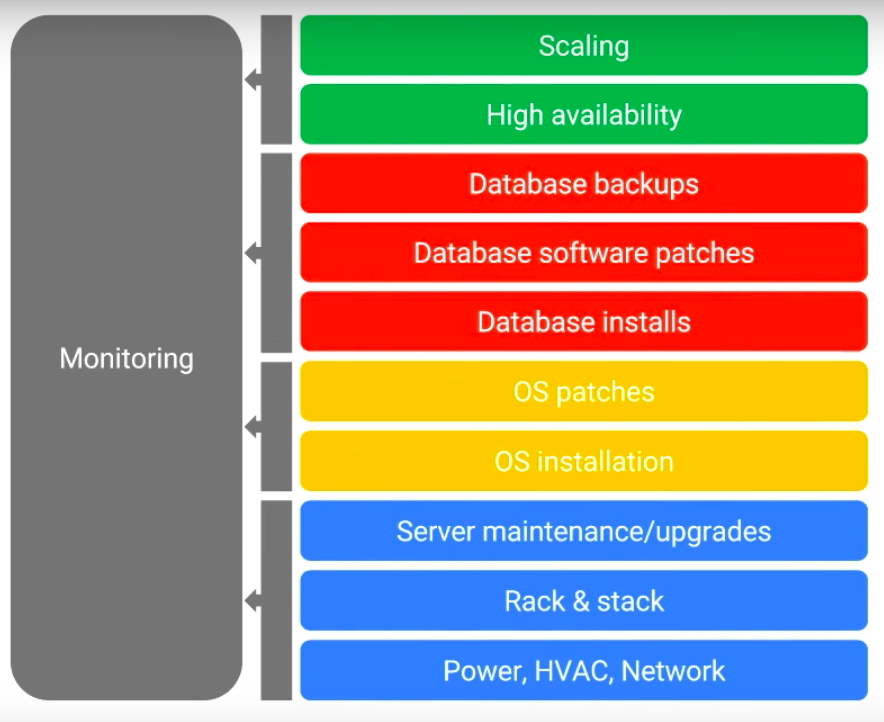
Credit: Google Next
- Bigtable provides auto sharding during the heavy transactions and takes care of the data storage.
- MegaStore Provides High availability and High consistency transactions with ACID.
- And finally, Datastore bring the traditional NoSQL things.
- Low Lock granularity improves the performance.
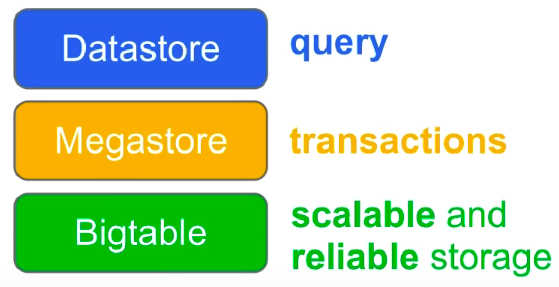
Credit: Google Developers
Replication: #
Google Datastore supports Region and MultiRegional replication. Multi Region replication only supports in few regions based on the region you are selecting while create your first Datastore kind. Region replication will automatically copy the data to multiple nodes which are in the multiple datacenters.
Europe and North America regions are supporting Multi Region Replication. Rest of the regions are support single region replication.
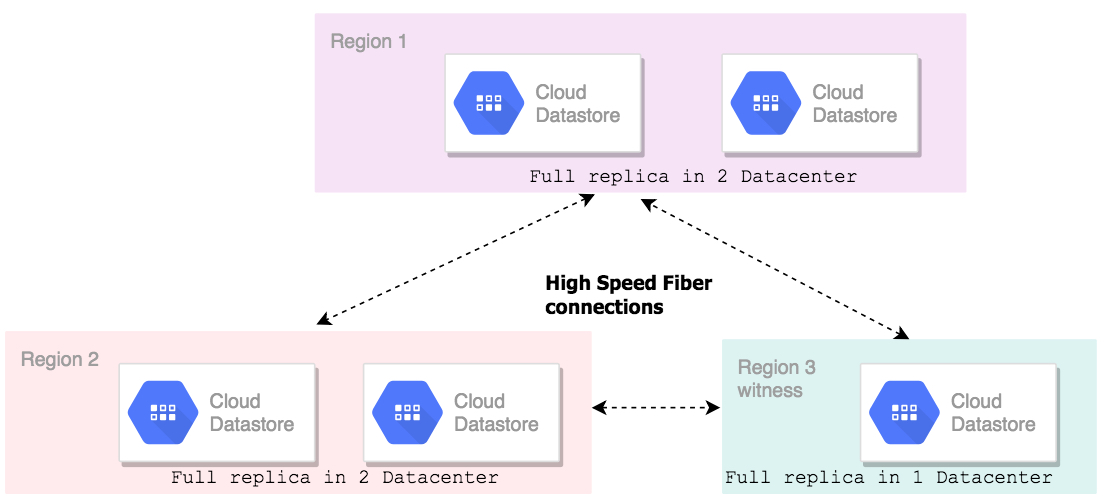
The above diagram explains the multi replication replication. Each Regions are interconnected with three independent fiber optics network. Two regions have the complete replica of the data in two different data centers. And the remaining one is having the data in one region called as a witness will tie-break during any one of the region went fail.
Consistancy: #
Datastore supports two consistency levels.
- Strong consistency
- Eventual consistency
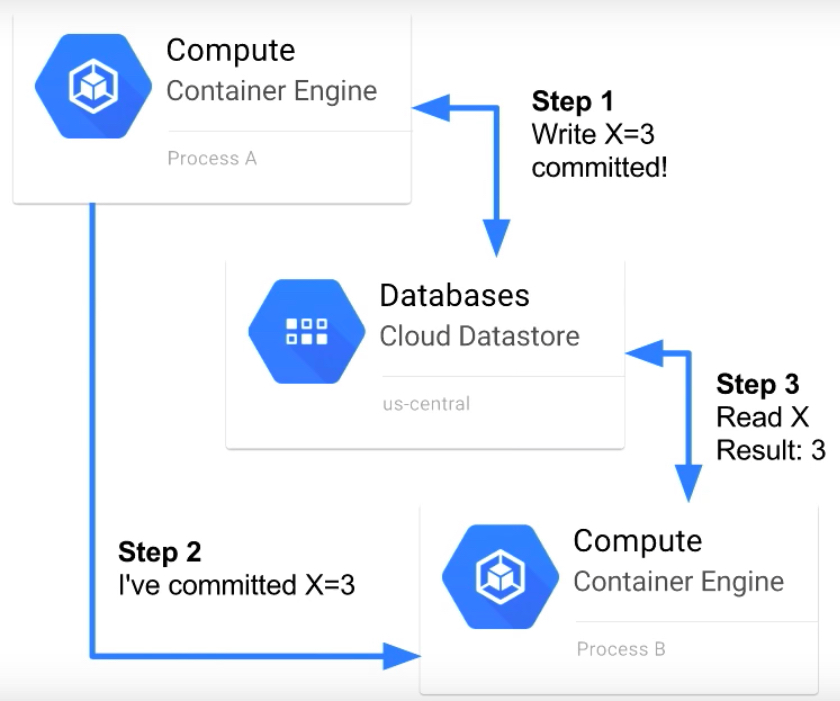
Strong Consistency: #
In strong consistency, Parallel threads will work together to on all data centers and regions. Strong consistency will occur while accessing,
- Key-Value Operation
- Entity Group (Ancestor query)
Example: Lets say you have user and orders table. In orders table, you are referring user_id column is common for both tables, means its a parent-child relationship (in Relational user_id id Primary key on the User table and in orders table its a foreign key). The table will look like below.

Now we are going to Update the orders for the user_id X to 3.
Then multiple parallel threads will start to update this value on all the regions.
If someone trying to access the Order for the user_id X during this update, their sessions will be locked until the update complete on all the regions.
Refer the below Diagram for this process.
Credit: Google Next
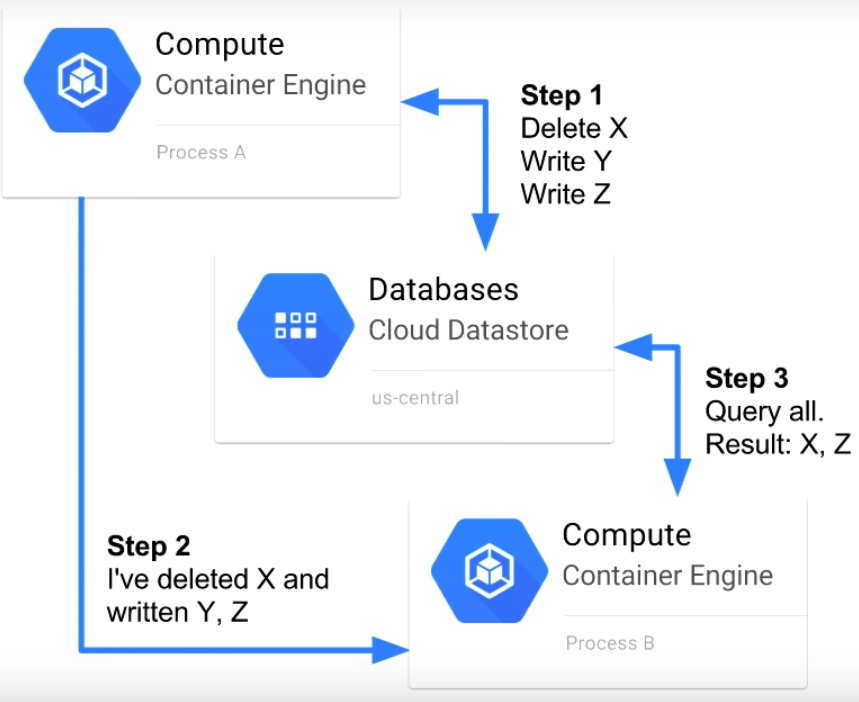
Eventual Consistency: #
Eventual consistencies are compared to Dirty Reads in a Relational database. This types of consistencies will occur when you are dealing with Non-Ancestor queries.
Example: Consider you have a kind which has only one property and it has only one value called X. Now you are going to delete the value X and insert two new values Y, Z.
In this process, the queries are not touching any Ancestor.
So parallel thread will delete the data X on the Region 1.
Meantime, someone reads the data in the kind on Region 2.
Due to eventual consistency, the data will take a bit time to replicate to Another region, but other users can able to read the old data.
Refer the below Diagram.
Credit: Google Next
Index: #
Index is the another huge topic in Datastore. We already read that BigTable will do Range scans only. But Google Datastore can work same as the other NoSQL databases. So it should support exact values search. Here the indices are coming to the picture.
In Datastore, Queries are executed on the Index scan.
So, if you check statistics of your Datastore, the index size will be larger than the entities. In relational databases, we need index for improving the performance. But in Datastore indices are need to scan your data. If you are scanning the data on an unindexed property, the query will fail.
Datastore has two types of index.
- Single properly index – Index on one particular property.
- Composite index – Index on multiple properties.
Bigtable will also create another table for index. Lets explain this with an example. Remember, Bigtable will do Range scan. In the index table, its also having the key-Value things but values of the property as Keys. So the actual data is in the key. A range scan is fine to get your data.
Single property index: #
Single Property index is created automatically by Datastore.
Select * from Person
where height < 72
Order by height DESC;In Bigtable, the property as Key and data is Value. So the Bigtable’s table will look like below and it’ll do a range scan on the KEY which is equal to the string height.
KEY : VALUE
____________
name : X
name : Y
height: 71
height: 72
height: 73
height: 75
height: 80The BigTable scan will return all the values. But we need < 72. Here index table will work. In the index table, the Bigtable’s values are Key means 71,72,73,75,80 are the Keys for Index table. So while performing the range scan on the index table, we can get the data
Another Visual Example of Index Scan:

Credi: Google Developers
Composite Index: #
Composite index will work in the same way as Single property Index. It’ll help on filtering on multiple properties and Order by on multiple columns.
Create composite Index:
You can create composite index in a yaml file and use gcloud util to create it on the Datastore. The below yaml file will create the composite index on order_date and user_id properties.
indexes:
kind: orders
properties
- name: order_date
- name: user_idVisual Example:

Credit: Google Devloper
To learn more about the Query Execution and Query Restrictions:
Credit: Google Devloper
To learn more about the Query Execution and Query Restrictions: