Migrate Greenplum Partitions To BigQuery With Airflow/Python
Migrate the Greenplum partition table to BigQuery. It creates an empty table on BigQuery along with partitions like Greenplum.
We have many airflow operators to help migrate or sync the data to Google BigQuery. If the target table is not there, then some operators like GCS to BigQuery operators will automatically create the table using the schema object. But these operators will just migrate the table DDL without the partition information. During any DataWarehouse migration, we have to keep the table’s partitions as well. In this blog, Im sharing my experience with migrating some of the Greenplum tables DDL to BigQuery with partitions.
Greenplum Partitions: #
Greenplum supports two different partitions.
- range partitioning: division of data based on a numerical range, such as date or price.
- list partitioning: division of data based on a list of values, such as sales territory or product line.
- Also, we use a combination of both types.
You can use pg_partitions system table to see the detailed view of the table partitions.
BigQuery Partitions: #
BigQuery supports 3 different types of partitions.
- Ingestion time: Tables are partitioned based on the data’s ingestion (load) time or arrival time.
- Date/timestamp/datetime: Tables are partitioned based on a TIMESTAMP, DATE, or DATETIME column.
- Integer range: Tables are partitioned based on an integer column.
If you compare the BigQuery partition capability with Greenplum, all the BigQuery partitions are equivalent to the Range partition in Greenplum.
- So it won’t support the list partition.
- A combination of List and Range is not possible.
- Only one level of partitions are supported (or subpartitions are not possible)
Find the partition details: #
Considering the above 3 points, we’ll convert the Greenplum partitions with the following steps.
- Scan the giving table name in the pg_partitions table and find whether it is partitioned or not. Since we are interested in Range partition, so we’ll check whether this table has Range partition or not.
- Then the next step is to find the column that is used for partitioning.
- In Greenplum, it is just a range partition but in BigQuery we have to mention whether it is an integer range or DateTime. So we have to find the data type of the partitioned column, if it is
intthen its Integer partition, or if it istimestamp or timestampzthen its date time partition. - For the timestamp based columns, we have to mention the time unit like partition based on HOUR/DAY/MONTH/YEAR. So again in the
pg_partitionswe’ll get the information inpartitioneveryclausecolumn. - If it is an integer column then find the start and end values using
partitionrangestartandpartitionrangeendcolumns and the interval inpartitioneveryclausecolumn.
I created a python function to combine all these logics and generate information about the source partition.
Extract Table DDL: #
Now we have to extract each column and its data type for the given table, then we have to map the equivalent BigQuery data type. All the information has to be returned as JSON and it will be used as the BigQuery schema object. I used information_schema.columns to identify the column names and its data type. Here is what I have used for the data type mapping.
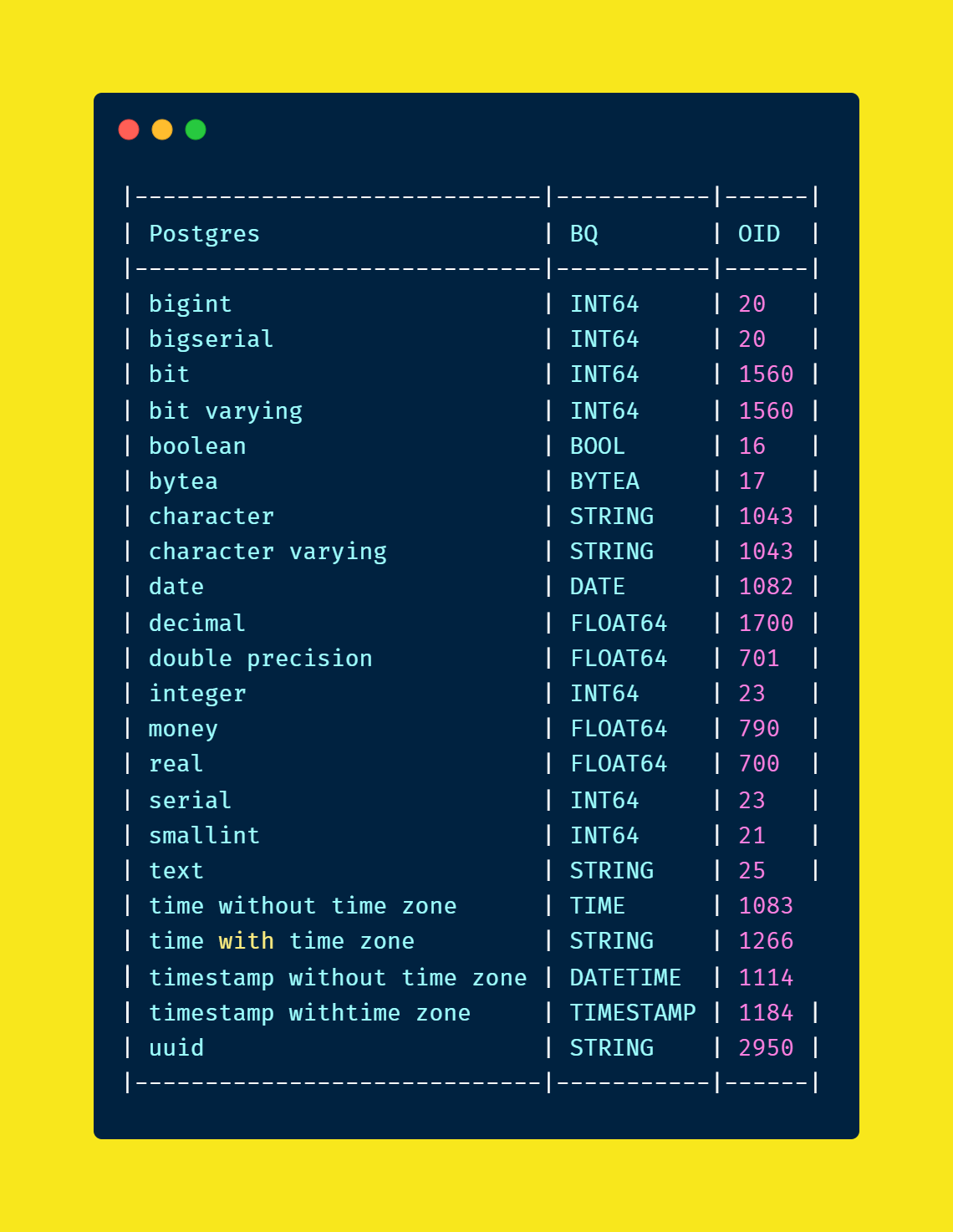
Generate the BigQuery Partition details: #
In airflow Bigquery hook, it won’t support the Range partition as a parameter, but we can use table_resource to pass the whole table’s properties. So the next step is to consolidate all the partition information and generate the JSON format. Here we are combining the schema and the partition details, then it’ll be passed as the table_resource in the BigQuery API.

Create the table via BigQueryHook: #
And we are going to use the BigQuery Hook (from the backport providers) to create the empty table using the table resource. If you are using an older version of Airflow(libraries from airflow.contrib then the hook doesn’t support the table_resource option).
You can use your own python code instead of airflow by just replacing this step. And here is my final version of the complete code.