Reconstruct RedShift STL_QUERYTEXT using AWS Athena
In my last post, I have experimented to reconstruct the complete stl_querytext table in RedShift using LISTAGG() function. But there is a limitation in that. If you read AWS Doc for LISTAGG, you can’t group the rows which are more than 65535 characters. What happens if we have tens of thousands of lines of SQL queries? It’ll throw the limitation error for sure. I didn’t find a much better solution in RedShift to solve this. So I decided to use other services which are cheaper to do this work. And that’s why you are here. Yes, this time I used AWS Athena an interactive analytics platform where we can query the data in an S3 bucket directly. Lets see how to reconstruct all the queries in stl_querytext table using Athena.
Unload the data: #
Athena can’t use the RedShift directly to query the data, we have to export the data into S3 bucket. Here we are going to do the same. But a minor change, the data in stl_querytext table has some special characters like \r and \n t what ill break our process in Athena. So while exporting the data, we have to replace then with whitespace.
Replace(Replace(text, '\r', ''), '\\n', '') AS text But unfortunately, I was not able to use this SQL syntax in unload command, it didn’t replace anything. (I have request AWS Support to solve this, I’ll this blog once I got the solution), but we can create a view on top of the stl_querytext to replace these characters.
CREATE VIEW v_stl_querytext
AS
(SELECT userid,
xid,
pid,
query,
SEQUENCE,
Replace(Replace(text, '\r', ''), '\\n', '') AS text
FROM stl_querytext) Now lest unload the data to S3 bucket, make sure you have a proper IAM role to access the S3 bucket and change the bucket name and path as per your need.
unload ('select * from v_stl_querytext')
to 's3://mybucket/querytxt/querytxt.csv'
iam_role 'arn:aws:iam::1111111111:role/Access-S3'
REGION 'ap-south-1'
HEADER
delimiter '|'
ADDQUOTES;Update: 2020-03-30 #
Instead of creating the view, you can use the following query to unload the data.
-- Credit: AWS team
unload ('SELECT userid,
xid,
pid,
query,
sequence,
replace(replace(text,
\'\\\\n\',\'\'),\'\\\\r\',\'\') AS txt
FROM stl_querytext')
to 's3://mybucket/querytxt/querytxt.csv'
iam_role 'arn:aws:iam::1111111111:role/Access-S3'
REGION 'ap-south-1'
HEADER
delimiter '|'
ADDQUOTES;If you want to add compress, please enable it, which will improve your Athena query performance.
Athena Table: #
Now lets go and create a table in Athena to query the data in S3.
CREATE EXTERNAL TABLE `stl_querytext`(
`userid` string COMMENT 'from deserializer',
`xid` string COMMENT 'from deserializer',
`pid` string COMMENT 'from deserializer',
`query` string COMMENT 'from deserializer',
`sequence` string COMMENT 'from deserializer',
`text` string COMMENT 'from deserializer')
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'escapeChar'='\\',
'quoteChar'='\"',
'separatorChar'='|')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://mybucket/querytxt/'
TBLPROPERTIES (
'skip.header.line.count'='1') We are almost done, now let’s write some SQL queries to reconstruct the stl_querytext table.
Reconstruct the SQL Queries: #
with cte as
(SELECT userid,
xid,
pid,
query,
sequence,
text,
row_number()
OVER (PARTITION BY userid, xid,pid,query
ORDER BY sequence) AS rank
FROM stl_querytext
GROUP BY userid, xid,pid,query,sequence,text
ORDER BY rank)
SELECT userid,
xid,
pid,
query,
array_join(array_agg(text),
'') as text
FROM cte
GROUP BY userid, xid,pid,query
ORDER BY query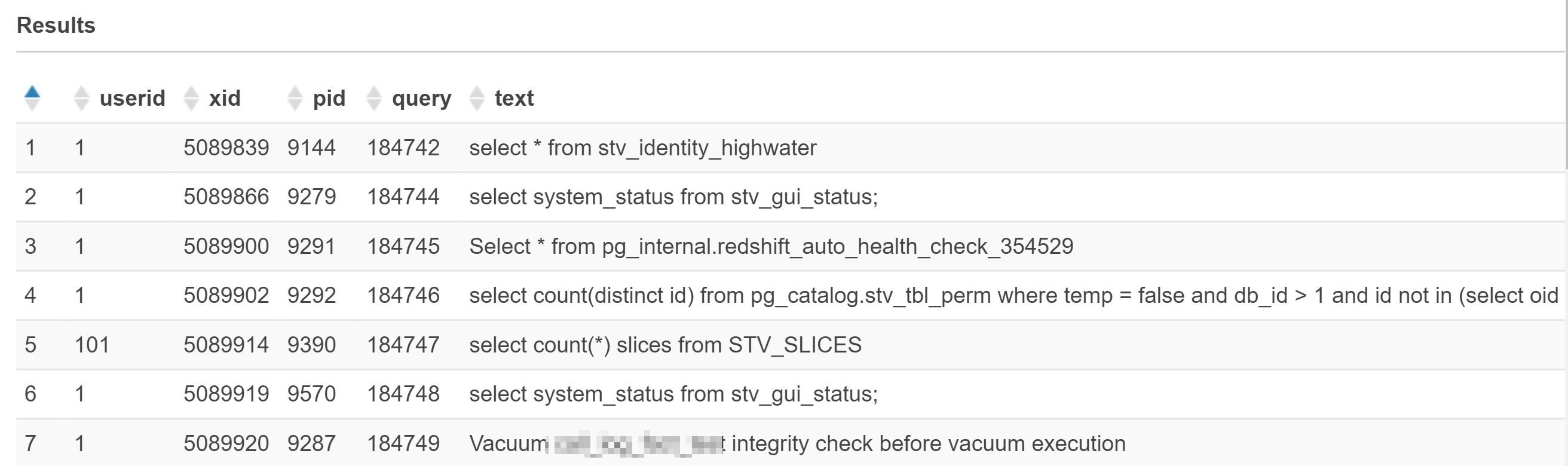
Ohhh!!! Im impressed by its performance, Last time, when I perform the same activity on RedShift some times it took a min to complete, but Athena did a great job. Try it out and comment below if you face any issues.
Update: 2020-03-30 #
I faced an issue with Athena recently, what happened is the array_agg() is not maintaining the query order. So some queries may be incorrect in the result reset. We can solve them by using array_join(array_agg(text ORDER BY sequence), '') AS text and again this syntax will not support in Athena because it 1.7x version. Im not sure when AWS is going to update the Athena’s presto verison. But if you want to use presto in EMR, it’ll work. Use the following query.
with cte AS
(SELECT userid,
xid,
pid,
query,
sequence,
text,
row_number()
OVER (PARTITION BY userid, xid,pid,query
ORDER BY sequence) AS rank
FROM stl_querytext
GROUP BY userid, xid,pid,query,sequence,text
ORDER BY rank)
SELECT userid,
xid,
pid,
query,
array_join(array_agg(text ORDER BY sequence), '') AS text
FROM cte
GROUP BY userid, xid,pid,query
ORDER BY query;