RedShift COPY Command From SCT Agent - Multiple Tables
AWS SCT extraction agents will extract the data from various sources to S3/Snowball. We have an option to export multiple tables at a time. But all these tables data will be randomly distributed to multiple subdirectories based on the number of extraction agents. When you are trying to import the data from S3 to RedShift, you may not know which directory contains what table’s data. So We cannot generate a COPY command for this data. I have already blogged an article to understand the directory structure of the AWS SCT extraction agent. I highly recommend reading that blog before executing these scripts.
Multiple random output folders: #
In my case, I had 7 AWS SCT extraction agents. During the export process, I have selected 40+ tables. Here is the output of the SCT Agent’s output from S3.
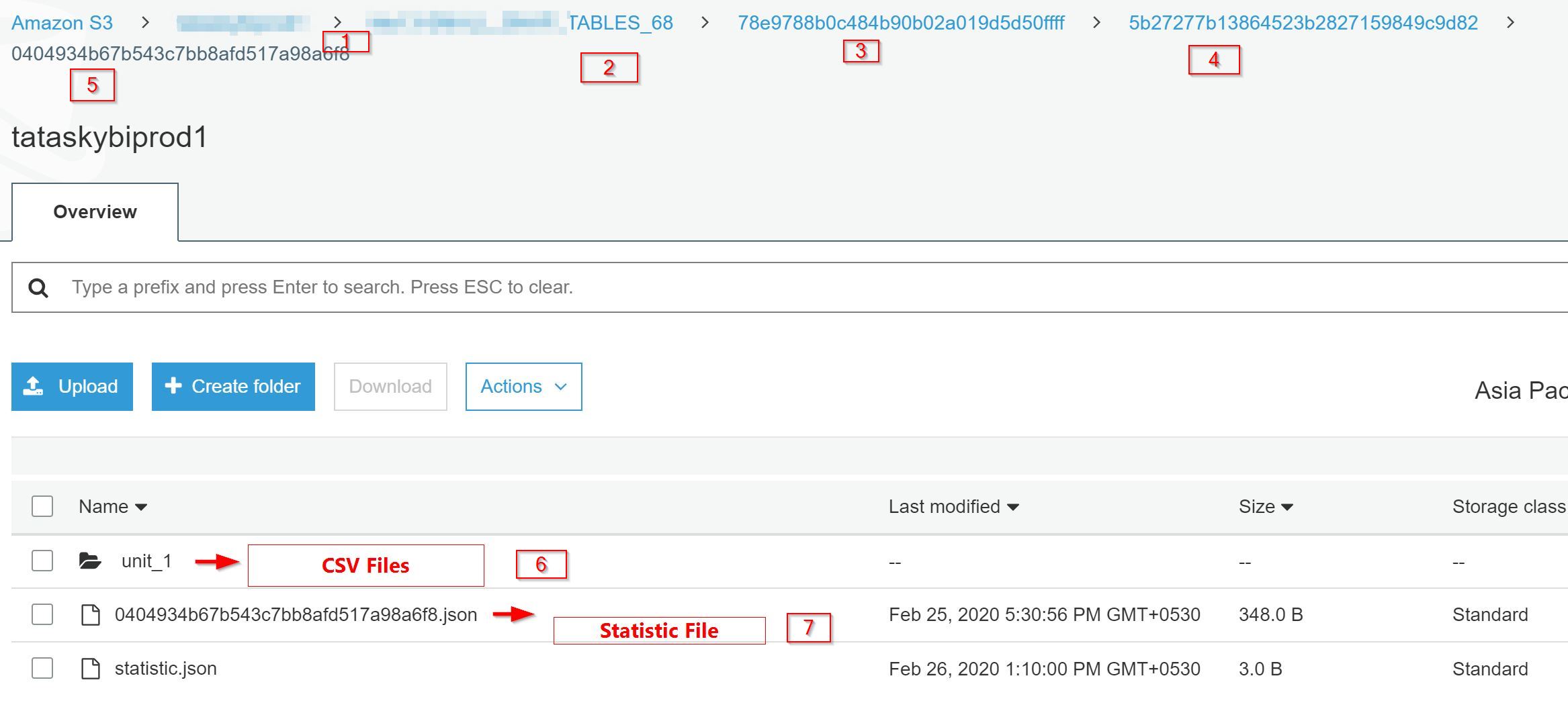
- Bucket Name
- Folder Name that I gave during the export
- Extraction Agent ID
- Subtask ID
- Task ID
- CSV files (8 files in one Unit folder)
- Stats File - The naming conversion is
taskid.json
The actual CSV files are located under the Unit_X folder. One unit folder contains 8 files(as per my SCT settings).
How to find Table Names: #
The only way to find the table name is by extracting the table name from the Stats file. Each task ID folders contains a bunch of CSV files that belong to the same table. So if we extract the table name from the stats file, then we can easily generate the COPY command.
unit.manifest file: #
Every Unit folders contain a file called unit.manifest. This is a manifest file that has the exact S3 path for all the 8 files in that particular Unit folder. So we can directly use this manifest file to import the data into RedShift via COPY command.
If you have 16 CSV files, then you will get 2 different unit folders(Unit_1 and Unit_2). But both the unit folders contain the unit.manifest file. And the name is also the same(unit.manifest).
Logic behind this script: #
Once again, I recommend you to read my previous blog to understand this concept. List all files from S3 and grep the status files(its a JSON file, so grep JSON)
- Step #1: Download all the stats file that you got the list from the above step.
- Step #2: List all the
unit.manifestfiles from all the Unit folders recursively. (This will give you a full path of the manifest file). And put all the manifest files path into a file.
There is a common string between the stats file and the unit.manifest file’s path(the full path that you got from step 2) is the task ID.
Example: unit.manifest path:
s3://bucket/10tables-export/123abc/456def/678ghi/unit_1/unit.manifest
Each task ID contains its own stats file. For the above manifest file, the task ID is 678ghi. So this folder should have the stats file.
Stats file path:
s3://bucket/10tables-export/123abc/456def/678ghi/678ghi.json
678ghi is the common string between the manifest file and the stats file.
- Step #3: Pick the stats file one by one and then extract the
task IDandTableName
stats file example:
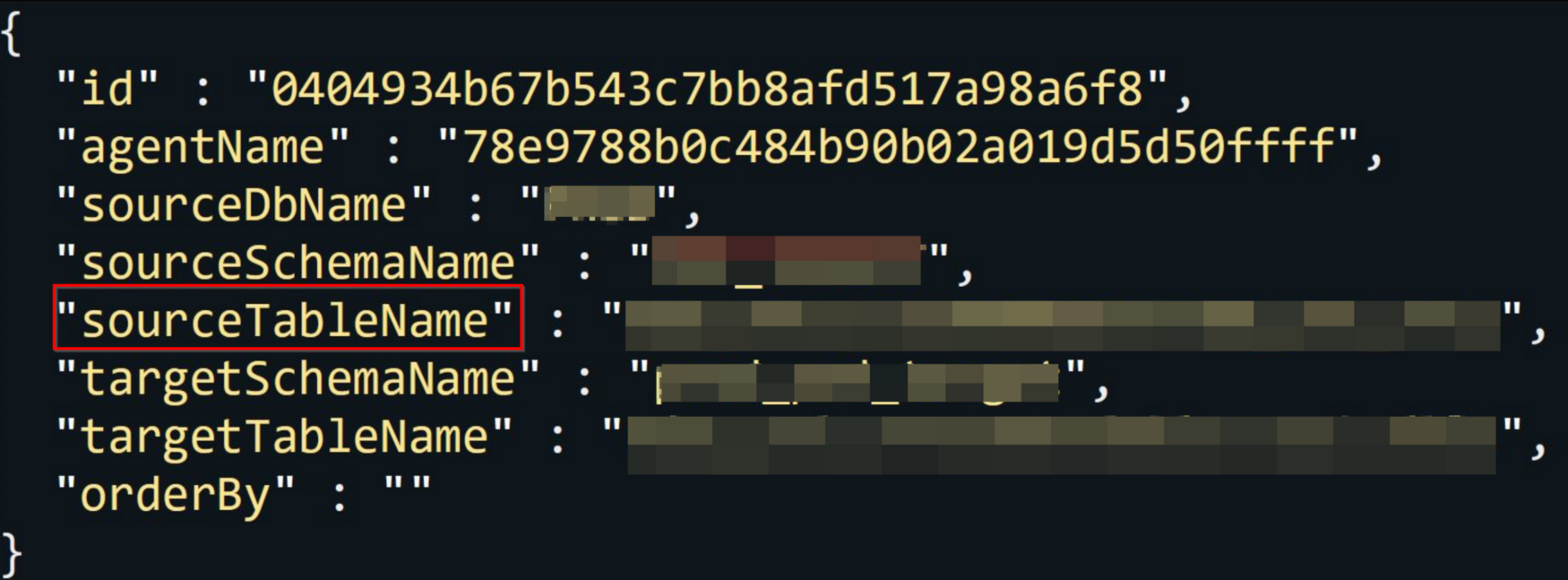
- Step #4: Grep the task ID from the file where we saved all the manifest file’s path. Now that manifest belongs to the table name that we extracted from step 3.
- Step #5: Put the grep output into a new file. Naming conversion is
table_name.unit.mainifest(we already extracted the table name at step 3). - Step #6: Loop the next stats file and repeat the step 3 and 4.
At this stage you have all manifest files and they are organized by table wise.
- Step #7: Now Just download these manifest files table by table.
- Step #8: Extract the CSV file path(from the manifest file) and put all the manifest files(belongs to the same tables) CSV file path into a single file.
- Step #9: Generate the COPY command.
Get the list of stats files #
aws s3 ls --recursive s3://myexport-bucket/10tables-export/ | grep "json" | grep -v 'statistic.json' | awk -F ' ' '{print $4}' > /root/group-tables/group-tables-id-file-list
Download all the stats files #
mkdir -p /root/group-tables/group-tables-id-files/
count=0
while read -r id_file
do
aws s3 cp s3://myexport-bucket/$id_file /root/group-tables/group-tables-id-files/ &
((++count % 20 == 0 )) && wait
done < /root/group-tables/group-tables-id-file-list
Get all the manifest files list (with full path) #
aws s3 ls --human-readable --recursive s3://myexport-bucket/10tables-export/ | grep "unit.manifest" | awk -F ' ' '{print $5}' > /root/group-tables/group.manifest.list
Separate manifest files Table wise #
mkdir -p /root/group-tables/manifest-list/
for files in /root/group-tables/group-tables-id-files/*
do
id=$(echo $files | sed 's\/root/group-tables/group-tables-id-files/\\g'|sed 's/.json//g')
table_name=$(cat $files | jq '.targetTableName' | sed 's/"//g')
manifest_files=$(grep -rn $id /root/group-tables/group.manifest.list | awk -F ':' '{print $2}' )
echo $manifest_files | sed 's/\s\+/\n/g'| sed '/^$/d' >> /root/group-tables/manifest-list/$table_name.manifest
done
Download the Manifest files - Table wise #
mkdir -p /root/group-tables/manifest_files/
for files in /root/group-tables/manifest-list/*
do
table_name=$(echo $files | awk -F '/' '{print $5}' | sed 's/.manifest//g')
mkdir -p /root/group-tables/manifest_files/$table_name
file_num=0
count=0
while read -r l_manifest
do
aws s3 cp s3://myexport-bucket/$l_manifest /root/group-tables/manifest_files/$table_name/unit.manifest.$file_num &
file_num=$(( $file_num + 1 ))
((++count % 20 == 0 )) && wait
done < $files
done
Merge all the manifest files into a single manifest file. #
for mf_files in /root/group-tables/manifest_files/*
do
table=$(echo $mf_files | awk -F '/' '{print $5}')
files=$(ls /root/group-tables/manifest_files/$table)
for file in $files
do
cat /root/group-tables/manifest_files/$table/$file | jq '.entries[]' >> /root/group-tables/manifest_files/$table/unit.merge
done
cat /root/group-tables/manifest_files/$table/unit.merge | jq -s '' > /root/group-tables/manifest_files/$table/$table.manifest
sed -i '1c\{"entries" : [' /root/group-tables/manifest_files/$table/$table.manifest
sed -i -e '$a\}' /root/group-tables/manifest_files/$table/$table.manifest
done
Upload the new manifest file to S3 #
for mf_files in /root/group-tables/manifest_files/*
do
table=$(echo $mf_files | awk -F '/' '{print $5}')
aws s3 cp /root/group-tables/manifest_files/$table/$table.manifest s3://myexport-bucket/new-manifest-file/
done
Generate the COPY command: #
Please customize the options like region, file formation, compression, IAM role and etc.
mkdir /root/group-tables/copy-sql
for mf_files in /root/group-tables/manifest_files/*
do
table=$(echo $mf_files | awk -F '/' '{print $5}')
echo "COPY your_schema_name.$table from 's3://myexport-bucket/new-manifest-file/$table.manifest' MANIFEST iam_role 'arn:aws:iam::1231231231:role/Access-S3' REGION 'ap-south-1' REMOVEQUOTES IGNOREHEADER 1 ESCAPE DATEFORMAT 'auto' TIMEFORMAT 'auto' GZIP DELIMITER '|' ACCEPTINVCHARS '?' COMPUPDATE FALSE STATUPDATE FALSE MAXERROR 0 BLANKSASNULL EMPTYASNULL EXPLICIT_IDS" > /root/group-tables/copy-sql/copy-$table.sql
done
Conclusion: #
This script saved us a lot more time from exporting 5K tables one by one. Hope you find this helpful. Please feel free to leave a comment in case if you have any issues.