Why You Should Not Compress RedShift Sort Key Column
Generally its best practice to compress all the columns in RedShift to get the better performance. But you should not compress the sort key columns. If you have multiple column in your sort key then don’t compress the first column of the sort key.
RedShift using both early materialization and late materialization. In early materialization the data will be filtered at the first step before a join or a filter. But in late materialization, the row numbers will be filtered instead of the data. For late materialization its ok to compress the sort key column, but RedShift will not use Late materialization for all the queries.
To explain this in simple, we have illustrated with some images. This is not the actual RedShift block structure, but they have the similar structure.
The sort key columns contains the row number of the other column as well for that particular row. Lets consider the you have table with 3 columns.
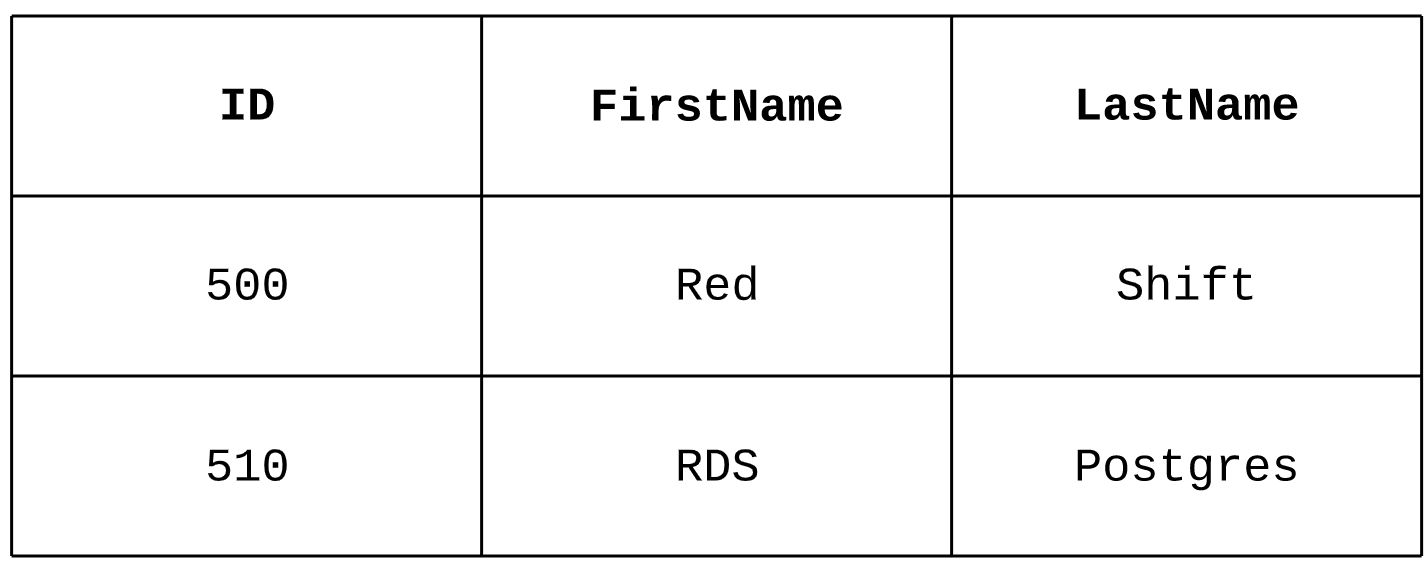
This tables will be stored in Redshift blocks along with its own row number or row_id.
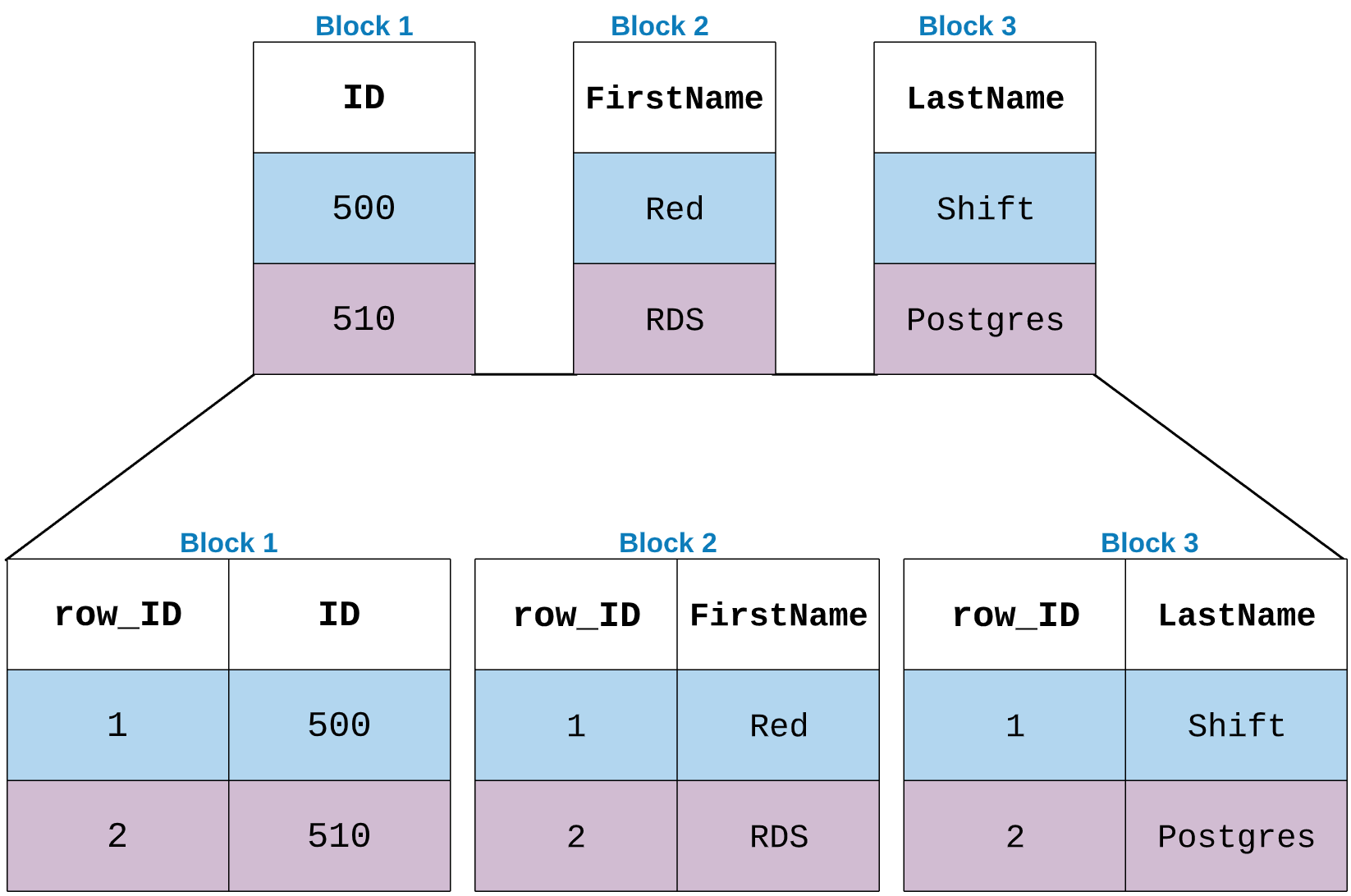
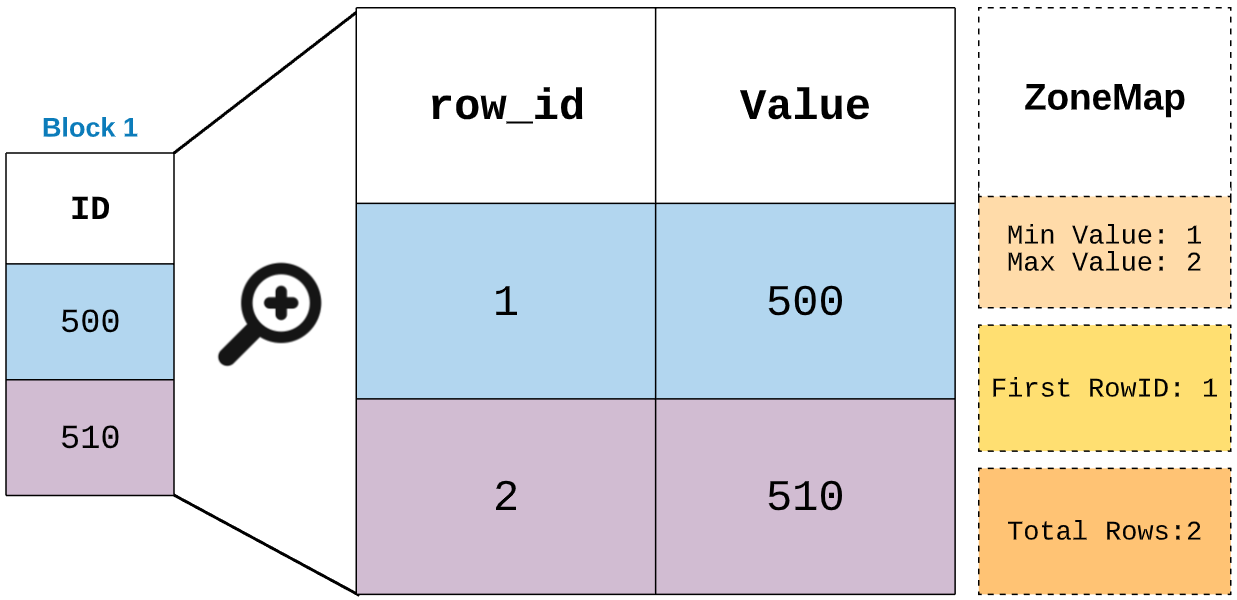
If you take a look at the Block1 structure with zone map it’ll be looks like below. We know Zone maps will contains the min and max values. But also they have some more meta data.
Similarly other blocks also will have the same structure. Lets explain this with an example.
select * from table where id = 1
- ID is the sort key column.
- RedShift will go to its zone map’s min and max values for the ID column, and it will find the block1 is the exact block where ID =1 lives.
- Now it’ll go to block 1 and scan all the values + row_id in that block.
- Then it has to check the
**firstname** columns block. Now it’ll take the ROW_ID (1, 2) that is fetched from the ID column’s block and go to Firstname column’s Zone MAP. - Then it’ll look into the zone map where ROW_ID 1 and 2 will fit.
- For FirstName column there is only block and the row ID 1,2 will fit in that block. So it’ll fetch all the values in that block.
- The same process will continue to fetch all the values from Block3.
- Now, it’ll do the user filter (id = 1)
- Then the final result will be provided to the client.
Real world Example: #
- Think a table with 30 rows. 2 columns (ID and comments)
- The ID column is compressed. After compression lets say the size is 800KB. So all the 30 rows will fit it single block.
- Now the comments column data is pretty large and even after applying the compression the size is 2.8MB. So it consumed 3 blocks.
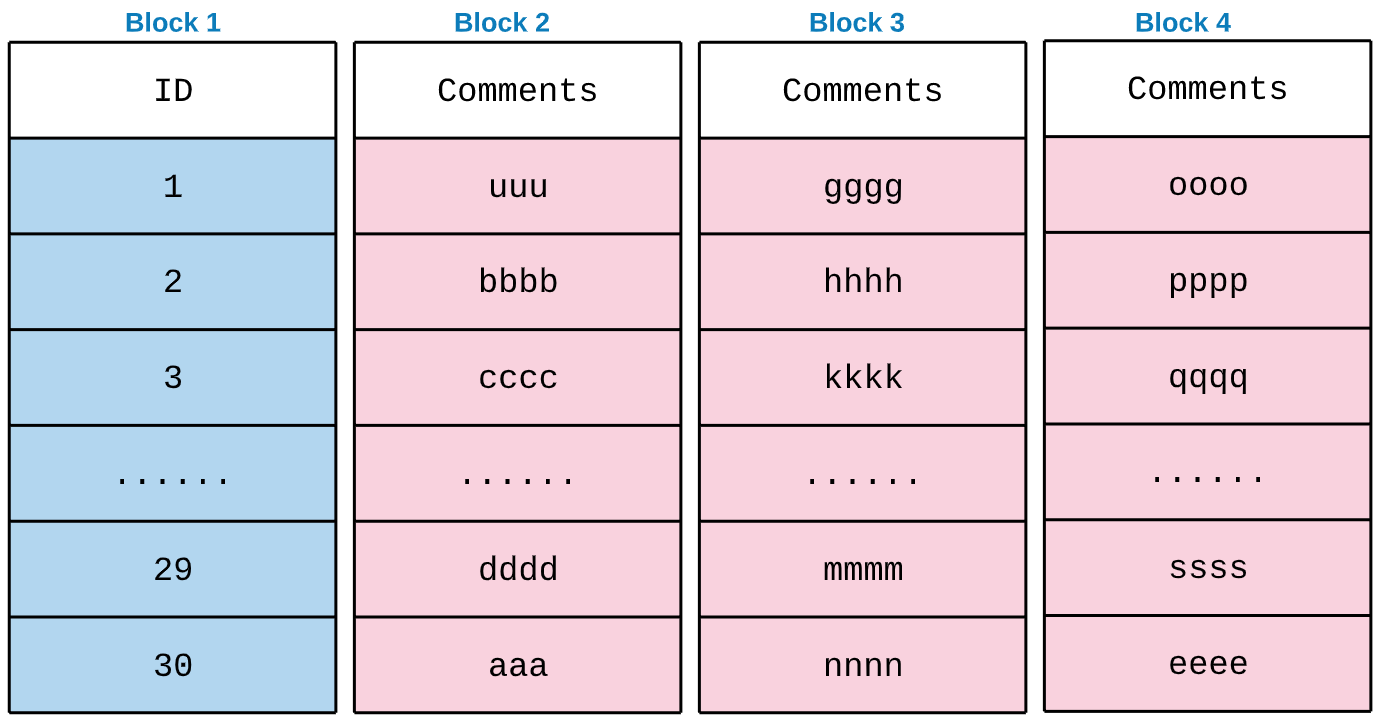
The block level structure is,
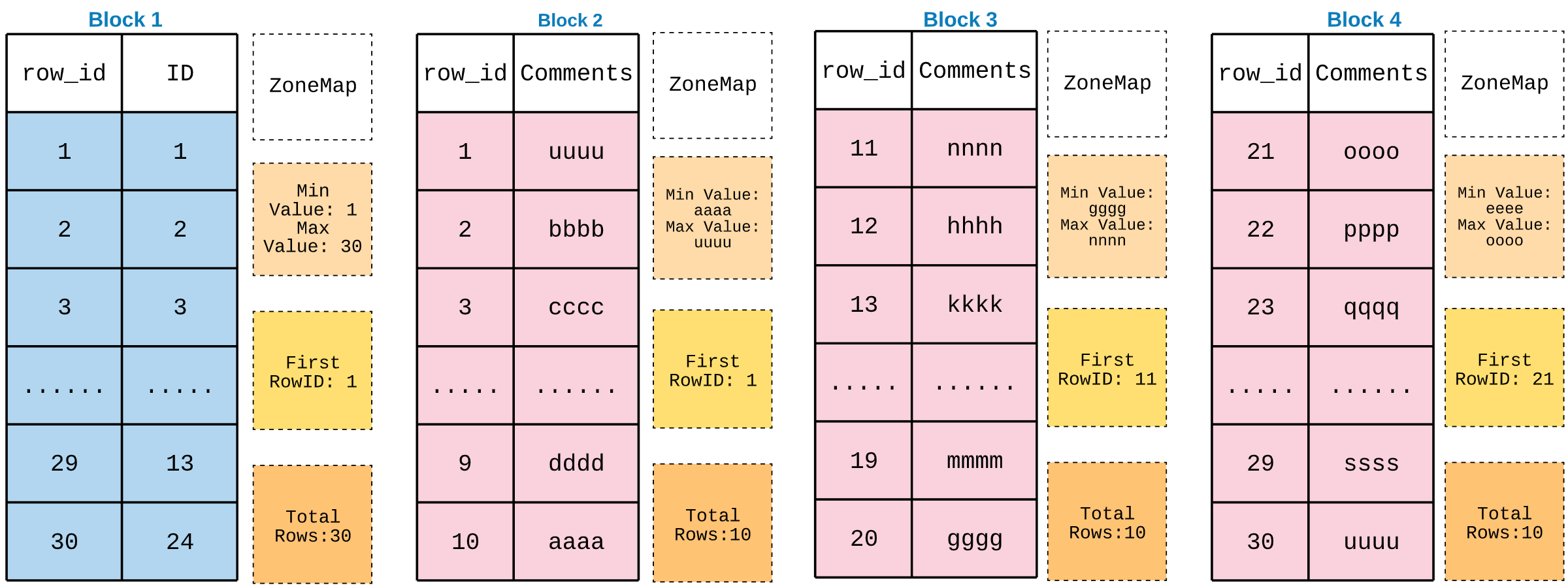
Query:
select * from table where id = 3;
Step 1: Find the block number for ID column
Block 1
Step 2: Read all the ID and its row number.
all 30 rows are read and their row_id as well
Step 3: Find the Comments columns data
Comments columns data will be fetched based on the Row_ID between 1 and 30
Step 4: Find the blocks from Row_ID 1 to 30
Block 2 - First Row ID = 1 --> Selected
Block 3 - First Row ID = 11 --> Selected
Block 4 - First Row ID = 21 --> selected
No other futher blocks for Comments column.
So Block 2,3,4 are selected to scan the data.
Step 5: Scan all the rows from comment columns.
30 Rows will be readed from 3 blocks.
Step 6: Combine both columns and Apply user filter.
Pick the row where id is 3
Step 7: Return the row to client.
Now from this execution, you can clearly see that we read all 3 blocks like full table scan to get just one row.
Lets take a look at this below block structure with uncompressed sort key.
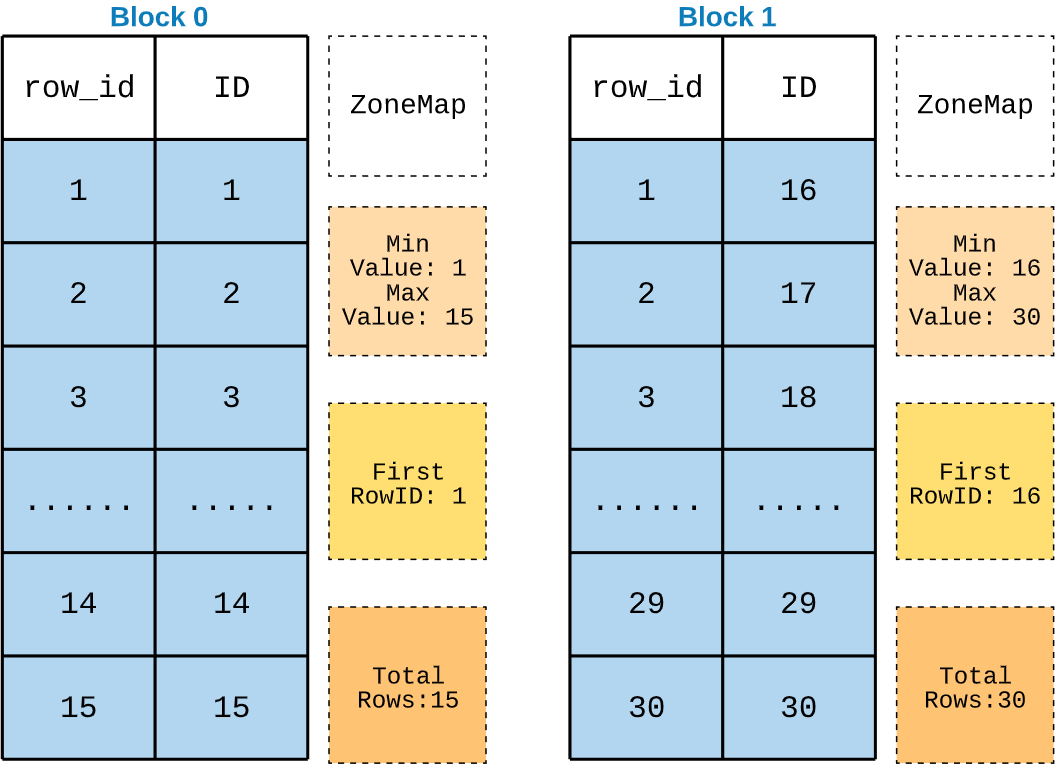
Now if you run the same query, it’ll scan all rows from Block 0. Then on comments column row_id 1 to 15 is need. So just block 2 and 3 is enough.
Block 2 - First ROW_ID =1 --> Selected
Block 3 - First ROW_ID =11 --> selected
Blokc 4 - First ROW_ID = 21 --> not needed
So block 2, 3 will be scanned.
Now its clear that we are scanning only 20 rows.
This is the reason we should not compress the sort key column or the first column of the sort key.
But why RedShift read full block on sort key column? #
In relation transaction debases, we have index and that will help us to read the necessary value. In sort key block, ID=3 is a single value. Instead of reading that single value and its ROW_ID why redshift is reading the whole block where ID=3 located?
Actually this is an OLAP database concept. It is called Early materialization. In this method first it’ll fetch all the data and do the filter. But in late materialization the filtering will happen before fetching the data, so only necessary data and it row_id is fetched. Then instead of scanning all the blocks it’ll read the exact block where the actual row_id lives. Then even if you compress the sort key column, it won’t affect much. This is cool right?
But is it not possible in RedShift? #
Partially NO, Redshift support both early and late materialization. But unfortunately, it’ll work for all the queries. Also the when it’ll use what materialization is also internal to RedShift. But anyhow it is highly recommended to do not compress the sort key column.
How to fix this problem? #
We cannot change/disable/enable the compression on the existing columns in redshift. So create a new table and copy the data from the existing table.