RedShift Tombstone Blocks a visual explanation
Redshift tombstone blocks and Ghost rows are similarly the same. Due to RedShift’s(aka PostgreSQL) MPP architecture and MVCC, the rows that we are going to update or delete will not be removed from the Disk. In RedShift’s term, the blocks are immutable. When we did the delete operation or Update the rows will be marked for deletion and these rows are called Ghost rows. They will be permanently removed while running the vacuum. While going deep into the storage optimization on RedShift I found something Tombstone blocks. In AWS there is only one doc that gives us a small description of this. It was not clear to me, I reached out to AWS for understanding this in a better way. So writing this blog to share my understanding with everyone.
Tombstone blocks are generated when a WRITE transaction to an Amazon Redshift table occurs and there is a concurrent Read. Amazon Redshift keeps the blocks before the write operation to keep a concurrent Read operation consistent. Amazon Redshift blocks can’t be changed. Every Insert, Update or Delete action creates a new set of blocks, marking the old blocks as tombstoned. – AWS Doc
Ghost rows: #
The rows that are inside an active blocks that are marked as deleted is called as Ghost rows.
Detailed explanation: #
- If a transaction starts reading something, then the data will be fetched from the block and serve it to the client.
- While the transaction is still active meantime someone wants to update something on the same block.
- Then RedShift will understand that this block is already using by a different transaction that is still not committed.
- RedShift will Copy that block into a new block and let the update process to use that new block.
- Once the update process is done, then the old block will be marked as deleted.
- Whenever the first transaction commits, then the old block will be removed.
- But unfortunately, sometimes these old blocks will never be deleted after the transaction commits. These blocks are called Tombstone blocks.
Sometimes tombstones fail to clear at the commit stage because of long-running table transactions. Tombstones can also fail to clear when there are too many ETL loads running at the same time. Because Amazon Redshift monitors the database from the time that the transaction starts, any table that is written to the database also retains the tombstone blocks. If long-running table transactions occur regularly and across several loads, enough tombstones can accumulate to result in a Disk Full error. – From AWS Doc.
A visual representation: #
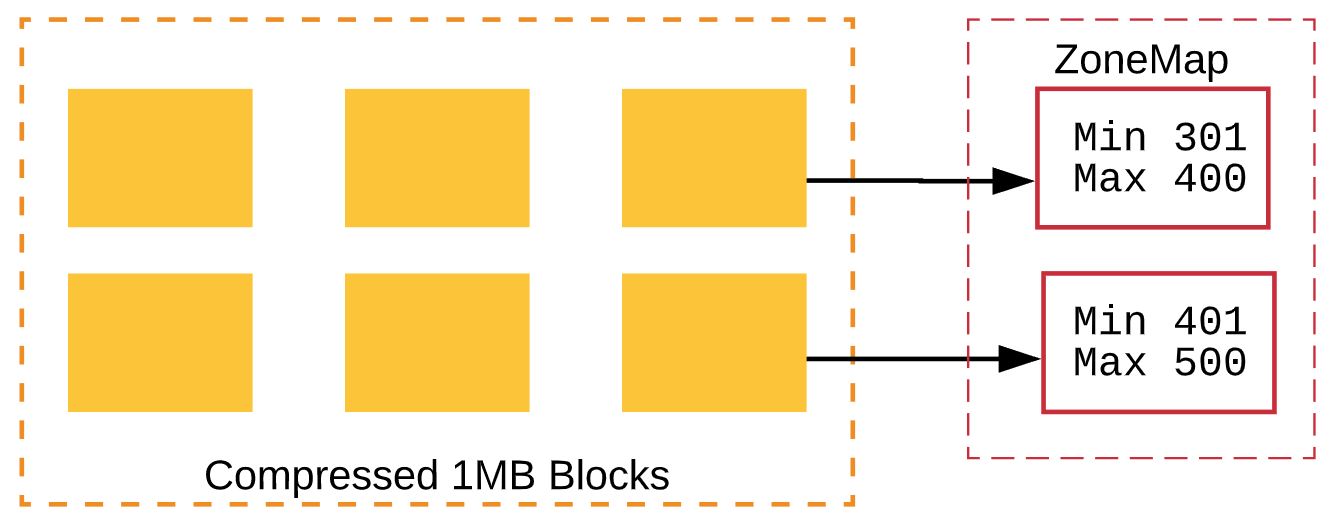
A normal block before any transaction.
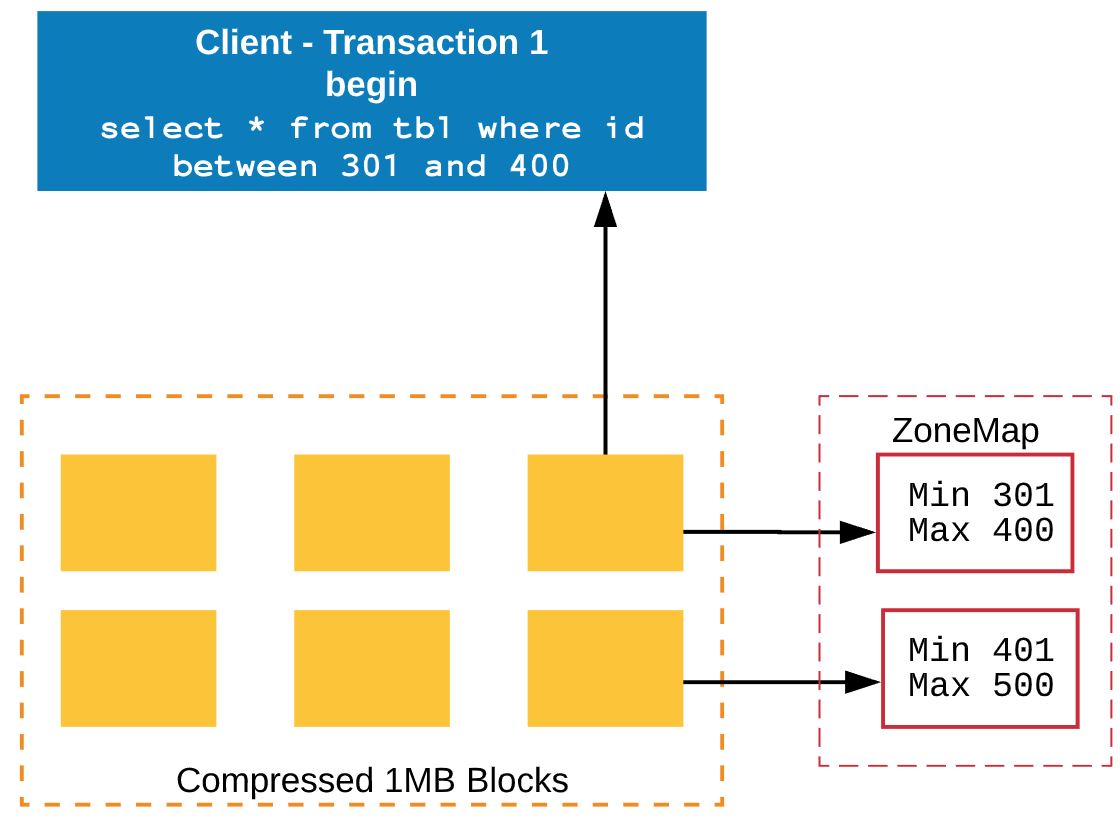
Transaction 1: Read the data from Block 3. But still its not committed.
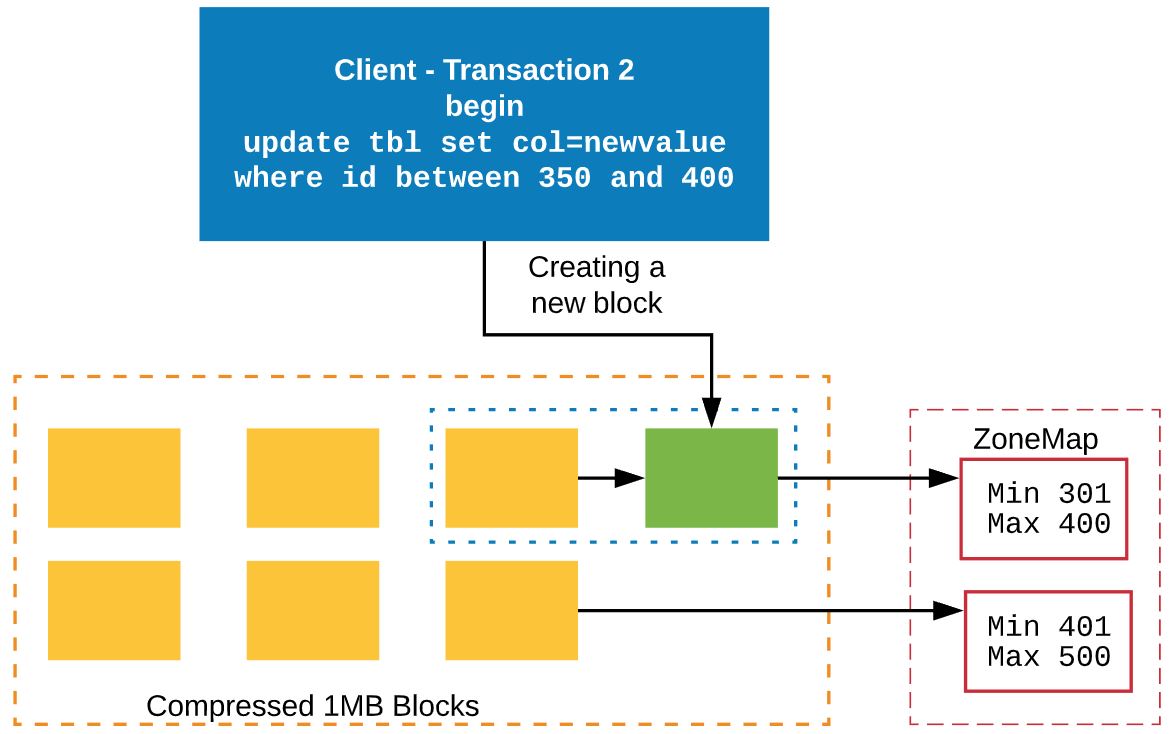
Transaction 2: Wants to update some rows in Block 3. But it is already used by Transaction 1. So it’ll clone that block to a new block.
Updates will be performed on the new block. Then it’ll commit the transaction.
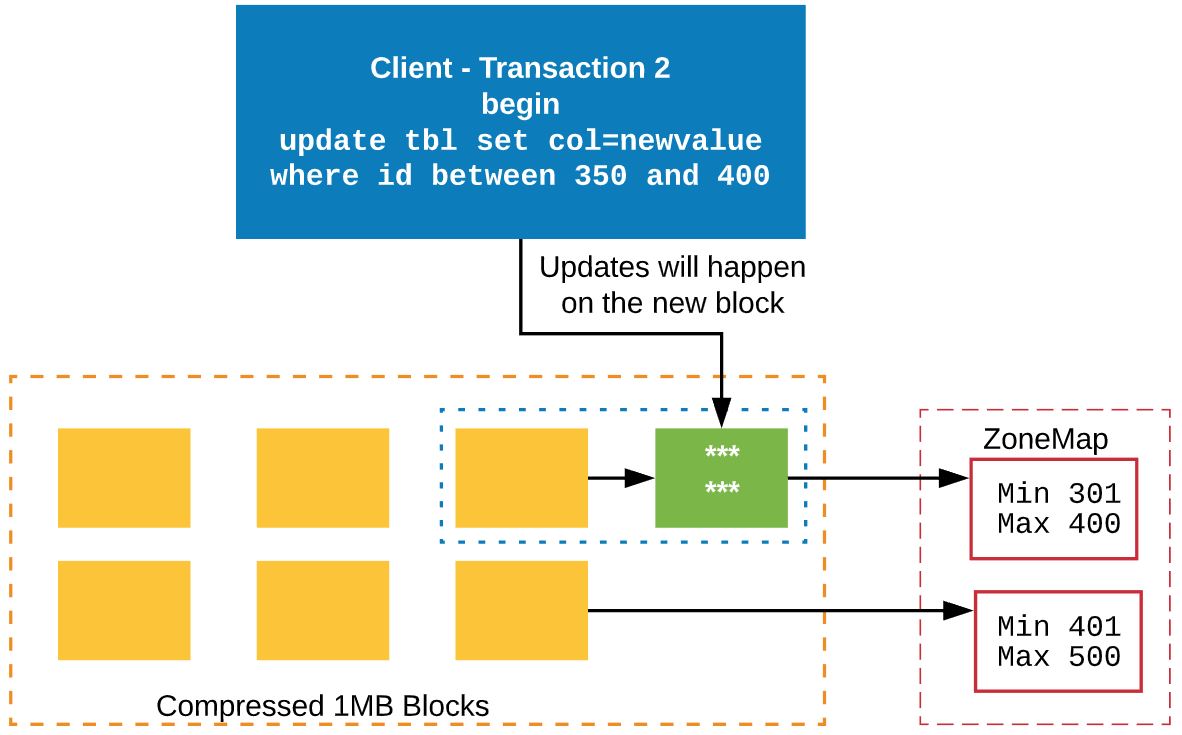
Then the old block will be marked as deleted.
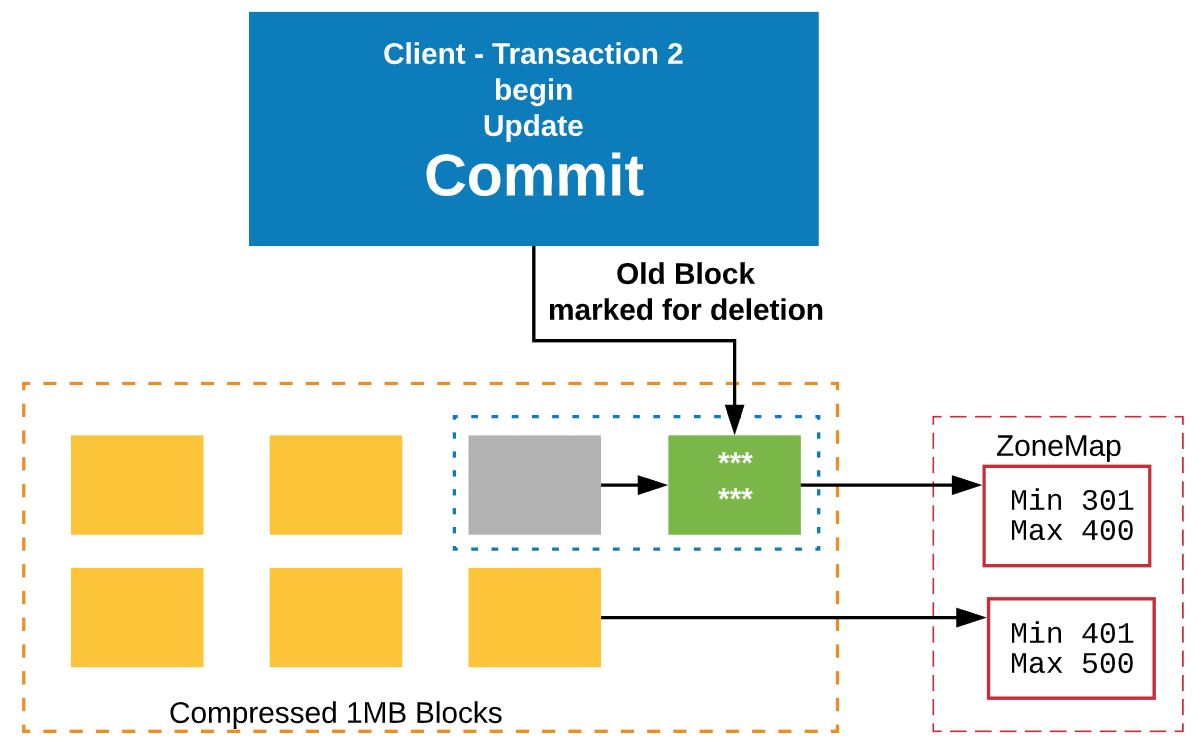
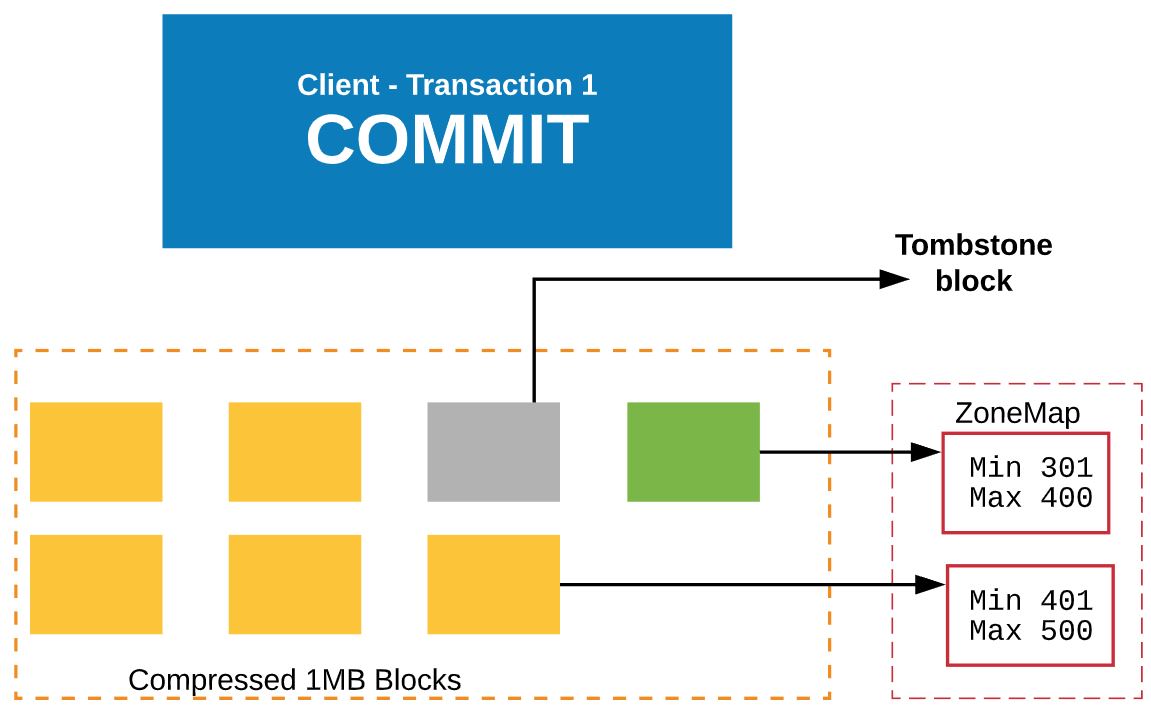
After Transaction 1 commits, it leaves the old block as it is. It’s is the tombstone block now.
Find the Tombstone blocks in RedShift? #
You can run the following command to find the list of tombstone blocks on each table.
-- Credits: AWS
SELECT Trim(name) AS tablename,
Count(CASE
WHEN tombstone > 0 THEN 1
ELSE NULL
END) AS tombstones
FROM svv_diskusage
GROUP BY 1
HAVING Count(CASE
WHEN tombstone > 0 THEN 1
ELSE NULL
END) > 0
ORDER BY 2 DESC; Also, you can use the following query to know then these blocks are added.
-- Credits: AWS
SELECT node,
Date_trunc('h', endtime) AS endtime,
Min(tombstonedblocks) min_tombstonedblocks,
Max(tombstonedblocks) AS max_tombstonedblocks
FROM stl_commit_stats
WHERE tombstonedblocks > (SELECT 0.1 * SUM(capacity) AS disksize
FROM stv_partitions
WHERE host = owner
AND host = 0)
GROUP BY 1,
2
ORDER BY 2,
1; Delete the tombstone blocks #
Generally, it’ll be deleted when the first transaction got committed, but sometimes it’ll not. So you have run the vacuum to delete them. If you want a shell script based utility to perform and automate vacuum, then refer this link.