RedShift User Activity Log In Spectrum With Glue Grok
RedShift user activity log(useractivitylog) will be pushed from RedShift to our S3 bucket on every 1hr internal. This file contains all the SQL queries that are executed on our RedShift cluster. But unfortunately, this is a raw text file, completely unstructured. So we can directly use this file for further analysis. I have already published a blog about this to query this data with AWS Athena with a lot of substring and split_part functions, but it’s not much efficient to scan a massive amount of data. That’s why I want to figure out a way to fix this. The only way to structure unstructured data is to know the pattern and tell your database server how to retrieve the data with proper column names. So I thought to use the Glue Grok pattern to define the schema on top of the user activity log files. Then use Spectrum or even Athena can help you to query this.
Glue Custom Classifier Grok Pattern: #
I found a grok pattern for this user activity log data on an AWS forum. But it didn’t work for me. Even I tried to change a few things, but no luck. But finally, with the help of AWS Support, we generated the working pattern.
\'%{TIMESTAMP_ISO8601:timestamp} %{TZ:timezone} \[ db=%{DATA:db} user=%{DATA:user} pid=%{DATA:pid} userid=%{DATA:userid} xid=%{DATA:xid} \]\' LOG: %{GREEDYDATA:query}Challenge in the data: #
The next challenge is, the AWS generate useractivitylog file is not in a proper structure. It’s one an ln-line text files. I mean if you have a long query then that particular query having a new line character.
'2020-05-22T03:00:14Z UTC [ db=dev user=rdsdb pid=91025 userid=1 xid=11809754 ]' LOG: select "table", "schema"
from svv_table_info
where "table" = 'mytable';It has to be in a single line.
'2020-05-22T03:00:14Z UTC [ db=dev user=rdsdb pid=91025 userid=1 xid=11809754 ]' LOG: select "table", "schema" from svv_table_info where "table" = 'mytable';So I created a Lambda function, that will be triggered whenever the new useractivitylog file is put into the Redshift. And it’ll remove all the new line characters and upload them back to the bucket with a different location.
Please refer to my previous blog to understand the lambda function setup.
import json
import urllib
import boto3
import re
import gzip
#S3 client
s3 = boto3.client('s3')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
#get the file name from the key
file_pattern='_useractivitylog_'
file_name = key.split('/')[8]
key_path=key.replace(file_name,'')
if file_pattern in key:
with open('/tmp/'+file_name, 'wb') as f:
#download the file
s3.download_fileobj('redshift-bucket', key, f)
#extract the content from gzip and write to a new file
with gzip.open('/tmp/'+file_name, 'rb') as f,open('/tmp/custom'+file_name.replace('.gz',''), 'w') as fout:
file_content = str(f.read().decode('utf-8'))
fout.write(file_content)
#read lines from the new file and repalce all new lines
#Credits for this piece PMG.COM
with open('/tmp/custom'+file_name.replace('.gz',''), 'r', encoding='utf-8') as log_file:
log_data = log_file.read().replace('\n', ' ')
log_data = re.sub(r'(\'\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}Z UTC)', '\n \\1', log_data)
newlog = re.sub(r'^\s*$', '', log_data)
#write the formatter lines to a file
with open('/tmp/cleansed_'+file_name.replace('.gz','')+'.txt', 'w') as fout:
fout.writelines(newlog)
#upload the new file to S3
s3.upload_file('/tmp/cleansed_'+file_name.replace('.gz','')+'.txt', 'redshift-bucket', 'custom-log-path/'+key_path+file_name.replace('.gz','')+'.txt')
else:
print("Skipping")You can use the same python code to run it on EC2 instance as well. Download the files to ec2 and then run this function.
Download the files to /tmp/input/
import json
import urllib
import boto3
import re
import gzip
import os
inputdir='/tmp/input/'
for file_name in os.listdir(inputdir):
with gzip.open('/tmp/input/'+file_name, 'rb') as f,open('/tmp/output/custom'+file_name.replace('.gz',''), 'w') as fout:
file_content = str(f.read().decode('utf-8'))
fout.write(file_content)
#read lines from the new file and repalce all new lines
#Credits for this piece PMG.COM
with open('/tmp/output/custom'+file_name.replace('.gz',''), 'r', encoding='utf-8') as log_file:
log_data = log_file.read().replace('\n', ' ')
log_file.close()
log_data = re.sub(r'(\'\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}Z UTC)', '\n \\1', log_data)
newlog = re.sub(r'^\s*$', '', log_data)
#write the formatter lines to a file
with open('/tmp/output/cleansed_'+file_name.replace('.gz','')+'.txt', 'w') as fout:
fout.writelines(newlog[1:])Create Spectrum Schema: #
Run the following query to create a spectrum schema. Make sure the following things are done.
- RedShift subnets should have Glue Endpoint or Nat Gateway or Internet gateway.
- RedShift IAM role to Access S3 and Glue catalog.
create external schema spectrum_schema
from data catalog database 'spectrum_db'
iam_role 'arn:aws:iam::123456789012:role/MySpectrumRole'
create external database if not exists;Crawl the data: #
Now create a Glue crawler to crawl the S3 bucket where we have the cleansed files. It’ll create a table for you. Two advantages here, still you can use the same table with Athena or use Redshift Spectrum to query this. The data source is S3 and the target database is spectrum_db.
Once the crawler finished its crawling then you can see this table on the Glue catalog, Athena, and Spectrum schema as well.
Create Table in Athena with DDL: #
If you are not happy to spend money to run the Glue crawler, then just simply paste the following DDL. (but replace the table name, S3 Location)
CREATE EXTERNAL TABLE `bhuvi`(
`timestamp` string COMMENT 'from deserializer',
`timezone` string COMMENT 'from deserializer',
`db` string COMMENT 'from deserializer',
`user` string COMMENT 'from deserializer',
`pid` string COMMENT 'from deserializer',
`userid` string COMMENT 'from deserializer',
`xid` string COMMENT 'from deserializer',
`query` string COMMENT 'from deserializer')
ROW FORMAT SERDE
'com.amazonaws.glue.serde.GrokSerDe'
WITH SERDEPROPERTIES (
'input.format'='\\\'%{TIMESTAMP_ISO8601:timestamp} %{TZ:timezone} \\[ db=%{DATA:db} user=%{DATA:user} pid=%{DATA:pid} userid=%{DATA:userid} xid=%{DATA:xid} \\]\\\' LOG: %{GREEDYDATA:query}')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
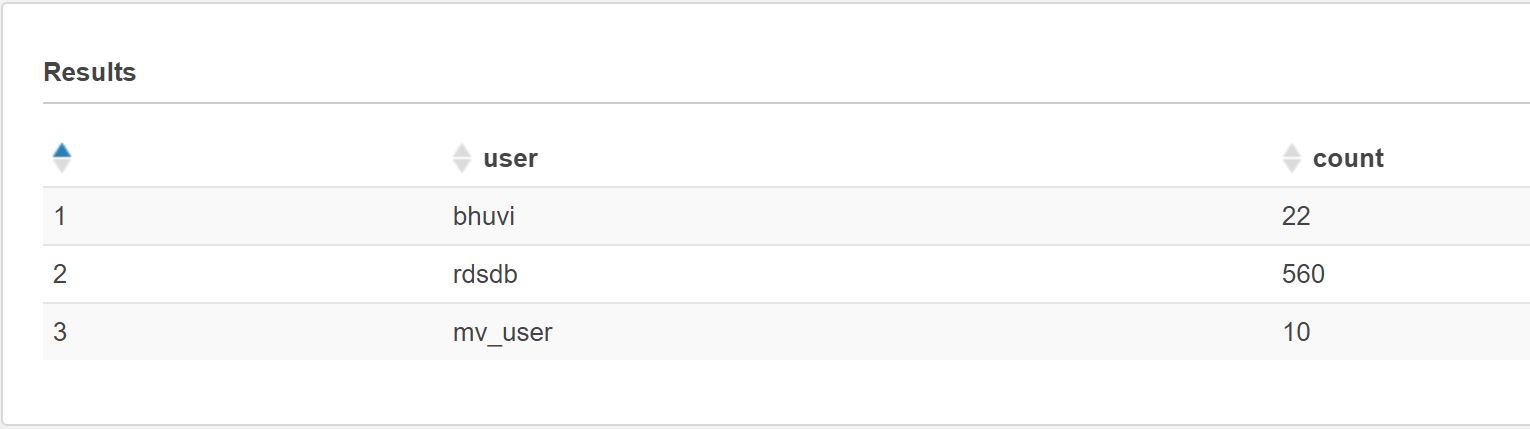
's3://mybucket/bhuvi-cleansed-data/'We are done now, Lets do a sample query. Here Im going to use Athena only, but the same query will on Spectrum.
select user,count(*)as count from activitylog group by user;