Setup Neo4j Causal Cluster On GCP And AWS
Neo4j is one of the top-rated Graph database platforms which supports community based Graph database and Enterprise as well. If you want to make the Neo4j database would be highly available, then we have to go with Enterprise edition that has the feature called Causal Cluster. This in blog, we are going to see how to setup and configure Neo4j causal cluster on GCP and AWS cloud platforms. The Neo4j’s documentation has well explained about this cluster setup, but I ran into some issues while deploying this on my own. Those issues made me write this blog.
Causal Cluster: #
This is nothing but a traditional replication mechanism. The whole cluster mechanism is behind the Raft algorithm. But it has some different terms.
- Core - A master and slave kind of setup. If the leader fails other core node will become a new master.
- Replica - Just a slave, but it’ll not participate in any election and it’ll never become the leader.
AWS/GCP: #
This blog just gives you simple steps to create a fresh Neo4j causal cluster. From AWS/GCP you just need to whitelist the IP address in the security group(AWS) and Firewall rules(GCP). Otherwise, all the steps are common for both deployments.
Setup Details: #
Here we are going to setup a 3 node cluster. We need a minimum of 2 core CPU and 2GB memory for this.
- Node 1 - 10.128.0.72
- Node 2 - 10.128.0.80
- Node 3 - 10.128.0.81
Install Neo4j on all the nodes: #
apt-get -y update
apt -y install openjdk-8-jre
wget -O - https://debian.neo4j.org/neotechnology.gpg.key | sudo apt-key add -
echo 'deb https://debian.neo4j.org/repo stable/' | sudo tee -a /etc/apt/sources.list.d/neo4j.list
sudo apt-get -y update
sudo apt-get -y install neo4j-enterprise=1:3.5.14
neo4j-admin set-initial-password 'root'Necessary Ports: #
- 5000 - discovery_listen_address
- 6000 - transaction_advertised_address
- 7000 - raft_advertised_address
- 7473 - HTTPS interface to access the Neo4j cluster in browser
- 7474 - HTTP interface to access the Neo4j cluster in browser
- 7687 - Used by Cypher Shell and by Neo4j Browser
- 6362 - Backup port to seed the data from the Leader node.
Please allow the above ports between all the nodes.
Configure the causal cluster: #
In our setup, we use 3 nodes as a minimum number of nodes to form a cluster, also we always need 3 runtime nodes to make the cluster up and running. Update the following values in the /etc/neo4j/neo4j.conf file.
Node 1
dbms.security.auth_enabled=true
dbms.connectors.default_listen_address=0.0.0.0
dbms.connectors.default_advertised_address=10.128.0.72
dbms.mode=CORE
causal_clustering.minimum_core_cluster_size_at_formation=3
causal_clustering.minimum_core_cluster_size_at_runtime=3
causal_clustering.initial_discovery_members=10.128.0.72:5000,10.128.0.80:5000,10.128.0.81:5000
causal_clustering.discovery_listen_address=0.0.0.0:5000
causal_clustering.raft_advertised_address=10.128.0.72:7000
causal_clustering.transaction_advertised_address=10.128.0.72:6000
Node 2
dbms.security.auth_enabled=true
dbms.connectors.default_listen_address=0.0.0.0
dbms.connectors.default_advertised_address=10.128.0.80
dbms.mode=CORE
causal_clustering.minimum_core_cluster_size_at_formation=3
causal_clustering.minimum_core_cluster_size_at_runtime=3
causal_clustering.initial_discovery_members=10.128.0.72:5000,10.128.0.80:5000,10.128.0.81:5000
causal_clustering.discovery_listen_address=0.0.0.0:5000
causal_clustering.raft_advertised_address=10.128.0.80:7000
causal_clustering.transaction_advertised_address=10.128.0.80:6000
Node 3
dbms.security.auth_enabled=true
dbms.connectors.default_listen_address=0.0.0.0
dbms.connectors.default_advertised_address=10.128.0.81
dbms.mode=CORE
causal_clustering.minimum_core_cluster_size_at_formation=3
causal_clustering.minimum_core_cluster_size_at_runtime=3
causal_clustering.initial_discovery_members=10.128.0.72:5000,10.128.0.80:5000,10.128.0.81:5000
causal_clustering.discovery_listen_address=0.0.0.0:5000
causal_clustering.raft_advertised_address=10.128.0.81:7000
causal_clustering.transaction_advertised_address=10.128.0.81:6000Cleanup the databases: #
Its a fresh cluster, so all the clusters should have the same data, here once we installed the neo4j software, then the neo4j service will automatically starts and it’ll create the default database calles graph.db on all the nodes. But according to the cluster, all the nodes should have same files and some metadata. Obiviously in our each node generated their own metadata in the graph database. Thats why we need to delete this system database from all the nodes.
service neo4j stop
rm -rf /var/lib/neo4j/data/databases/graph.db/
<or you can move it to another location>
mv /var/lib/neo4j/data/databases/graph.db/ /opt/ If you did’t do this step, or missed anyone of the node then you’ll get the error Store copy failed due to store ID mismatch Or in another case, if you already have some other databases with some data, then perform seed(its like a dump and restore from the existing node)
Start the Neo4j cluster: #
Now start the neo4j service on all the nodes. Order doesn’t matter here. Until all three nodes are up, your cluster won’t be formed. So all three nodes should be up.
service neo4j startOnce you stated it’ll wait for all three nodes are up and then perform an election to pick a Leader node. Once its up, we can query the cluster status via cypher-shell
cypher-shell -u neo4j -p root
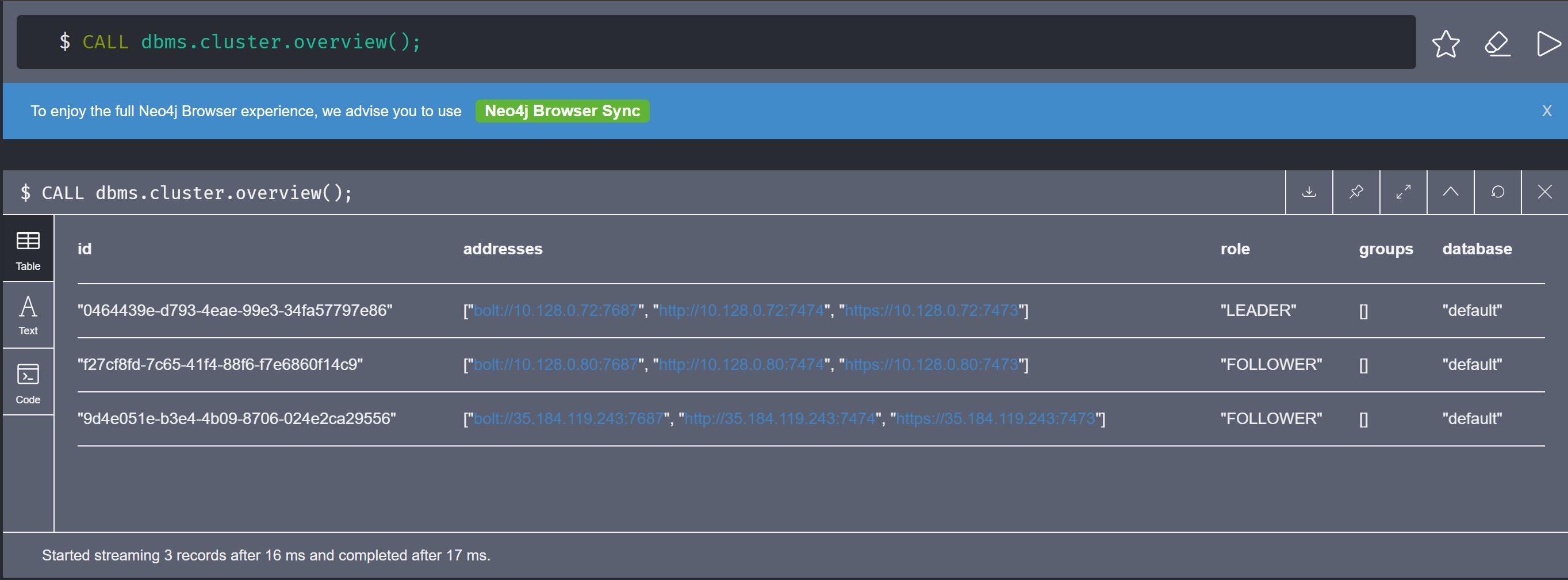
neo4j> CALL dbms.cluster.overview();
Also you can access the database from the browser with HTTPS interface. If you have private VPN between the neo4j node and the computer where you are trying to access the HTTPS interface then you directly use the Private IP with port 7374 Or if you want to use its public IP, then you have to change the dbms.connectors.default_advertised_address IP to the Node’s Public IP.
Conclusion: #
Again I’m confirming here is that this is just to give you a kickstart guide for neo4j cluster setup. You read more in-depth in the documentation page. I ran to some issues, but somehow I solved it. Here are some references to those errors.