BigQuery Data Pipeline Without Any Orchestrator Just CloudFunction And PubSub
A successful BigQuery Job completion will trigger another BigQuery job and scheduled queries via Cloud Function and PubSub sink from the StackDriver logging.
I was discussing with my team regarding a data pipeline for BQ, it’s a very simple pipeline, we are uploading some CSV files from the Relational Databases to GCS. Once the file arrived at the GCS, we can load it into a staging table and then merge it with the main table. Very simple pipeline. But I was thinking how can we orchestrate this without any orchestrator like Airflow, Matillion and etc. I have done a small PoC and wiring this blog post about that.
Orchestrate the pipeline: #
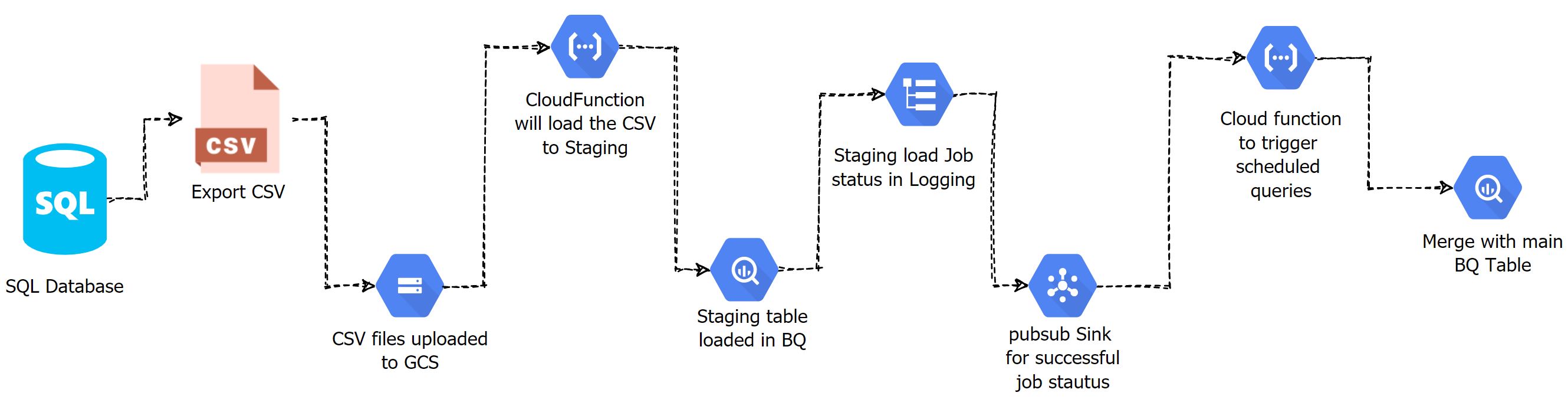
- Once the CSV uploaded to GCS, then trigger a CloudFunction.
- This CloudFunction will load the CSV file into my staging table.
- Then this job will push the completion status to StackDriver logging.
- A PubSub sink will trigger another CloudFunction when the job status is a success.
- This 2nd CloudFunction will trigger the Scheduled Query in BigQuery.
#1 Create the tables: #
For this PoC, Im going to use 2 tables. One for staging data and the other one is the main table.
- DataSet - my_db
- tblA - Staging
- target - Main table
Table Structure:
name STRING
id INTEGER
I have added a single row on the target table.
insert into `my_db.target` values ('aaa',2);
#2 GCS Bucket and directory stucture: #
I have a bucket with the name poc-bucket and inside I have the directory structure will looks like below.
gs://poc-bucket/sqlserver/tbla/
gs://poc-bucket/sqlserver/tblb/
gs://poc-bucket/sqlserver/tblc/
All the codes that I used here are based on strict naming conversion.
#3 Create Service accounts: #
We need 2 service accounts for Cloudction and BigQuery scheduled queries.
- CloudFunction - Storage Admin and BigQuery Admin
- BQ Scheduled Query - BigQuery Admin
#4 CloudFunction to load data into staging table: #
Region - Where your GCS and BQ tables are there. Trigger - Cloud Storage Event Type - Finalize/Create Bucket - poc-bucket Advanced - Select the service account Rutime - Python 3.8
Add these lines into the REQUIREMENTS.TXT file.
google-cloud-bigquery
google-cloud-storage
Function code: #
dataset = client.dataset('my_db') - replace with your Dataset name.
from google.cloud import storage
from google.cloud import bigquery
def hello_gcs_generic(data, context):
sourcebucket = format(data['bucket'])
source_file = format(data['name'])
# this split is based on my directory structure on GCS
table_name = source_file.split('/')[1]
input_file = source_file.split('/')[2]
uri = 'gs://poc-bucket/' + source_file
#troubleshooting
#print(input_file)
#print(table_name)
#print(source_file)
# BQ details
client = bigquery.Client()
dataset = client.dataset('my_db')
table = dataset.table(table_name)
# Job config
job_config = bigquery.LoadJobConfig()
job_config.source_format = bigquery.SourceFormat.CSV
job_config.skip_leading_rows = 1
job_config.autodetect = True
job_config.allow_jagged_rows = True
job_config.allow_quoted_newlines = True
job_config.fieldDelimiter = ','
job_config.write_disposition = 'WRITE_TRUNCATE'
load_job = client.load_table_from_uri(
uri, dataset.table(table_name), job_config=job_config)
# API request
print("Starting job {}".format(load_job.job_id))
load_job.result() # Waits for table load to complete.
print("Job finished.")
destination_table = client.get_table(dataset.table(table_name))
print("Loaded {} rows.".format(destination_table.num_rows))
#5 StackDriver PubSub Sink: #
Go to logging and create a new filter using the following lines. But replace these things.
- datasetId=“my_db”
- projectId=“my-poc”
- principalEmail=“[email protected] (CF service account)
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.datasetId="my_db"
protoPayload.serviceData.jobCompletedEvent.job.jobConfiguration.load.destinationTable.projectId="my-poc"
protoPayload.authenticationInfo.principalEmail="[email protected]"
protoPayload.methodName="jobservice.jobcompleted"
protoPayload.serviceData.jobCompletedEvent.job.jobStatus.state="DONE"
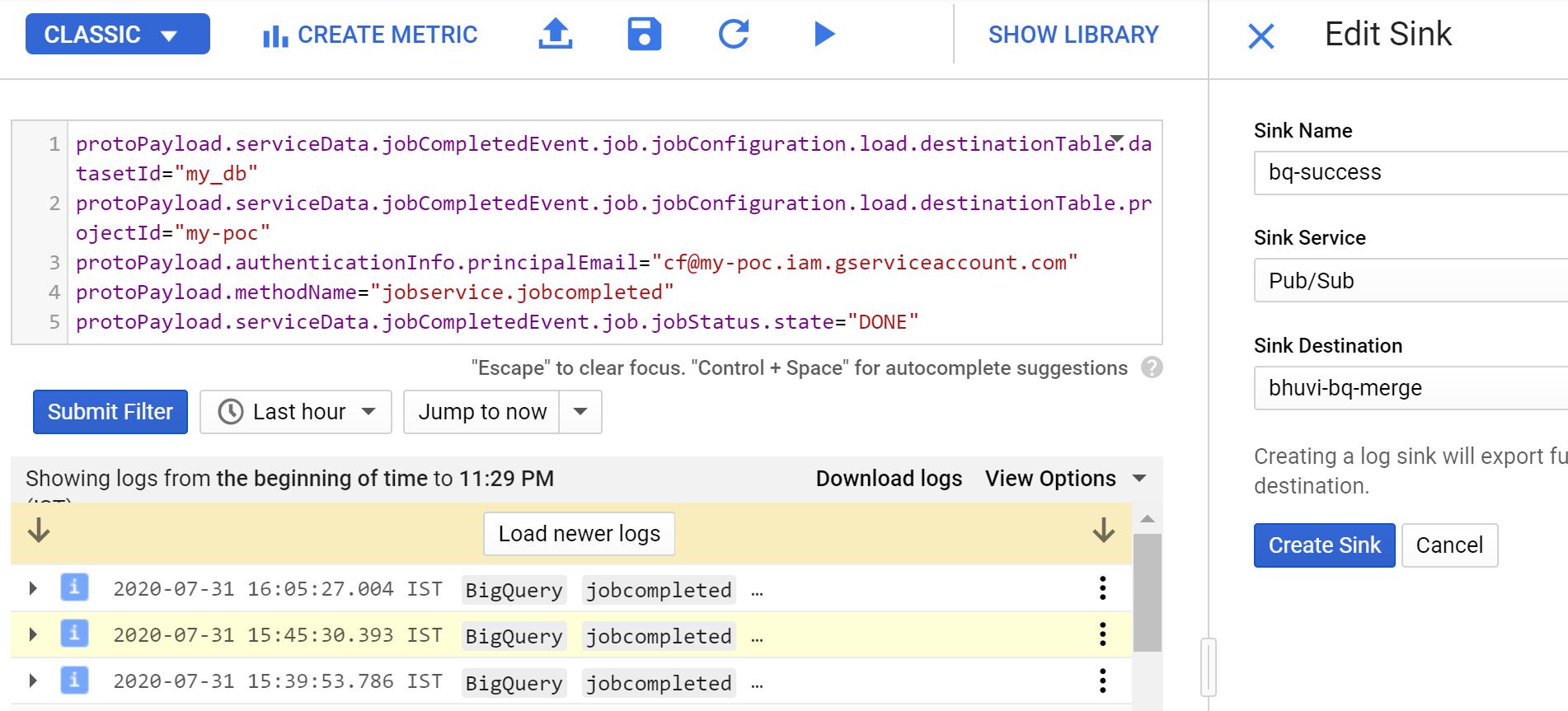
Now click on the create sink and the sink service as PubSub.
#6 Schedule Query in BQ: #
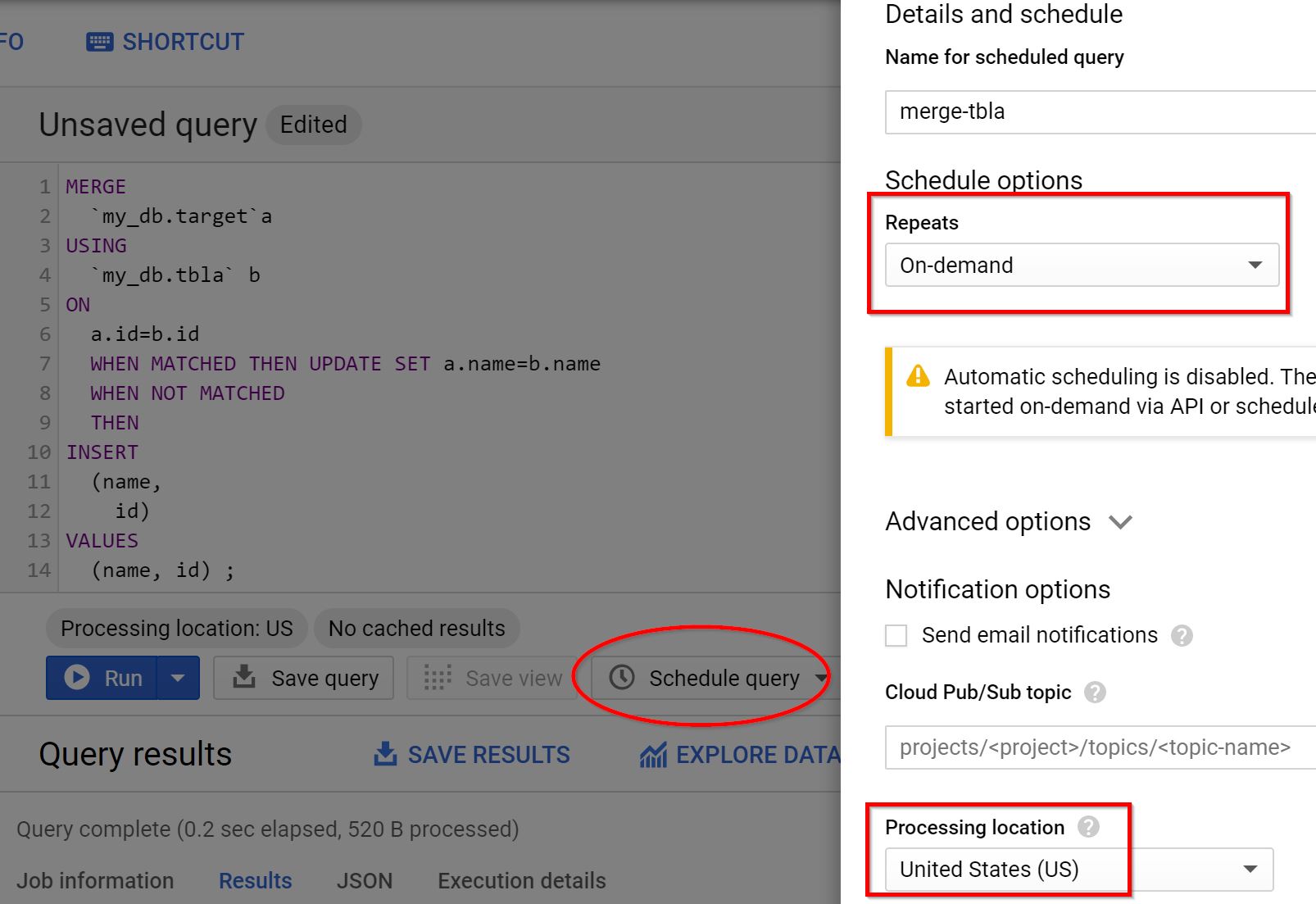
For mering the Data from the staging table to the main table, we can directly use a SQL query from the CloudFunction. But I want to do it in a different way. So we need to create a scheduled query that will run the merge SQL command.
MERGE
`my_db.target`a
USING
`my_db.tbla` b
ON
a.id=b.id
WHEN MATCHED THEN UPDATE SET a.name=b.name
WHEN NOT MATCHED
THEN
INSERT
(name,
id)
VALUES
(name, id) ;
- Name - merge-tbla
- Repeats - on-demand
- Processing location - US (if need, change it)
- Advanced - Select the service account
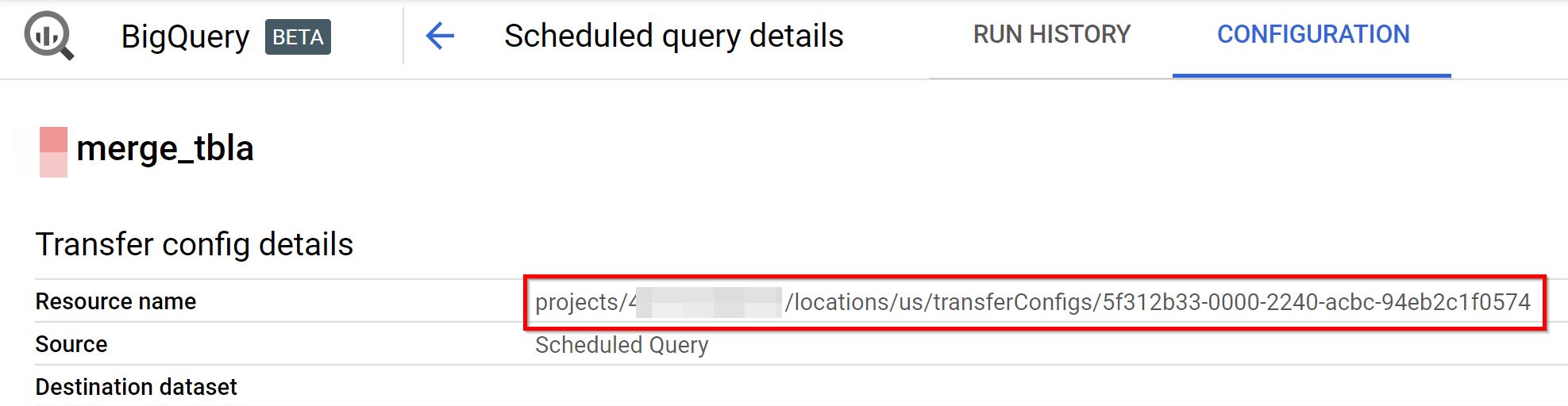
Once its created, go to Scheduled queries –> Query Name –> Config. You can see the resource name. This resource name will be used to trigger the scheduled query from the Cloud Function.
#7 CloudFunction to trigger scheduled query: #
Configuration - Same as the previous Cloud Function.
The logic behind this function is, once the job is done and its success, then it’ll create a log entry with the table name. In my scheduled query, I have the naming conversion as merge_tablename. Then it’ll list all the scheduled queries then and pick the resource name which matches the query name as merge_tablename.
REQUIREMENTS.TXT - google-cloud-bigquery-datatransfer
Main function Code: #
Replace parent=f"projects/poc-project" with your project name.
import time
import base64
import json
from google.cloud import bigquery_datatransfer_v1
from google.protobuf.timestamp_pb2 import Timestamp
def hello_pubsub(event, context):
pubsub_message = json.loads(base64.b64decode(event['data']).decode('utf-8'))
# get the table name
tbl=pubsub_message['protoPayload']['serviceData']['jobCompletedEvent']['job']['jobConfiguration']['load']['destinationTable']['tableId']
client = bigquery_datatransfer_v1.DataTransferServiceClient()
# list all Scheduled queries
list_squery = []
for data_source in client.list_transfer_configs(parent=f"projects/poc-project",data_source_ids=["scheduled_query"]):
x="{'"+format(data_source.display_name)+"':'"+format(data_source.name)+"'}"
list_squery.append(x)
# Get the correct query id for the required table.
value = json.loads(list_squery[0].replace('\'','"'))['merge_'+tbl]
# BQ Job configs
projectid = value.split("/")[1]
transferid = value.split("/")[5]
parent = client.project_transfer_config_path(projectid, transferid)
# Trigger after 10 secnds
start_time = bigquery_datatransfer_v1.types.Timestamp(seconds=int(time.time() + 10))
response = client.start_manual_transfer_runs(parent, requested_run_time=start_time)
print(response)
#8 Its demo time: #
Go to the GCS storage and upload the sample CSV file.
name,id
"aaa",1
And then see the data on both staging and target tables.
select * from `my_db.target`;
name: aaa
id: 1
Conclusion: #
We can do this pipeline in many ways, but my idea is without any orchestator I want to run, Also I need to trigger the scheduled queries when a particular job is success.